
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 스칼라
- Akka
- play2 강좌
- 파이썬 머신러닝
- 이더리움
- 하이퍼레저 패브릭
- CORDA
- 그라파나
- Actor
- Hyperledger fabric gossip protocol
- akka 강좌
- 안드로이드 웹뷰
- 주키퍼
- 스칼라 강좌
- 하이브리드앱
- 파이썬 강좌
- hyperledger fabric
- Adapter 패턴
- 파이썬 데이터분석
- 스칼라 동시성
- Golang
- 파이썬
- 파이썬 동시성
- 엔터프라이즈 블록체인
- Play2
- play 강좌
- 블록체인
- 플레이프레임워크
- 스위프트
- Play2 로 웹 개발
- Today
- Total
HAMA 블로그
 무들(Moodle) 2.0 이러닝 강좌 개발
무들(Moodle) 2.0 이러닝 강좌 개발
http://www.yes24.com/24/goods/9411715?scode=032&OzSrank=1 번역도 잘되있는 편이고, 구성도 깔끔해서 무들 시작하는 사람이라면 꼭 사서 읽기를 권합니다. 무들이 국내에서 흥한게 아니라서, 많이 팔리지 않았을거 같은데, 번역해주시는분이 있다는게 고마울따름입니다. 꼭 사서 봅시다!! 하지만 "백문이 불여 일타" 라는 점을 명심하세요. 직접 건드려보아야 오래 기억되고 빠르게 학습됩니다. P.S 무들은 개발자가 개발해주고 마는 시스템이 아니다. SI 사업처럼 개발해주고 땡? 전혀 다르다. 무들은 관리자, 선생님, 학생이 3위일체가 되서 만들어 나가는 시스템이다. 고로 멘토/컨설팅/관리자 측면으로 회사는 접근해야한다. 장기간의 서비스?
코스란? - 코스는 무들상에서 선생님들이 학습컨텐트를 학생한테 제공하는 공간이다. (무들의 핵심이다!!!!)- 코스는 관리자, 코스생성자, 매니저만 생성가능하다.- 선생님들은 컨탠트들을 추가한후에 필요에 따라서 재 조직화할수있다. 새로운 코스 추가하기일반권한의 선생님들은 새로운 코스를 추가할수없다. 다음 권한을 가진자들만이 추가할수있다. Administrator,Course Creator or Manager 코스 추가아래로 이동Administration>Site Administration>Courses>Manage courses and categoriesLink to add a new courseClick New course in the category page on the rightClick on th..
https://docs.moodle.org/29/en/Course_homepage#To_link_course_sections코스 홈페이지 내용 1 빈(blank) 코스의 표준 뷰 1.1 코스홈페이지를 구성하는 것들 2 코스 섹션2.1 코스 섹션 편집하기 2.2 코스 섹션 이동하기2.3 코스 섹션 삭제하기2.4 코스 섹션들 링크하기 3 블럭4 액티비티 와 리소스 5 코스홈페이지에서 엘리먼트 편집하기 6 팁과 트릭 6.1 많은 액티비티를 가진 코스안의 아이템들을 이동하기 7 코스홈페이지 능력들8 그밖에것들 빈 (blank) 코스의 표준 뷰 이번 예는 싸이트의 새로운 인스톨에 대한 표준 디폴트 코스홈페이지에 대한것이다. 이번 예와는 다른 모습을 가진 다양한 코스를 만들수있는 코스 옵션들이 있다. 이 예제 코스..
https://docs.moodle.org/29/en/Managing_a_Moodle_course 번역 무들 코스(Course) 매니징 무들에서 코스는 선생님이 학생들에게 가르킬 리소스와 액션을 추가하는 구역/부분 이다.다운로드될 문서가 있는 간단한 페이지가 될수도있고 , 상호관계를 통한 학습이 진행되게 복잡하게 구현될수도있다.다음을 예로 보자 What is a course in Moodle? 코스페이지는 태스크를 포함하는 중앙섹션으로 구성된다. 그리고 옵션으로 사이드에 블럭이 있다. 코스 선생님은 코스 홈페이지 ( course homepage ) 의 레이아웃으로 컨트롤을 가지며 언제든 바꿀수있다. 진행상태(학습상태) 는 여러가지 방법으로 흔적을 (tracked) 남길수있다. 학생들은 자동적으로 관리자에..
 무들 (moodle) 2.9 설치하기 for Windows
무들 (moodle) 2.9 설치하기 for Windows
윈도우에서 테스트용도로 무들을 사용해보기 위한 설치~ 1. http://download.moodle.org/windows/ 에서 Moodle 2.9+ 다운로드 이 패키지들은 무들 플러스를 포함한다. 이것은 윈도우즈 상에서 무들을 실행시키기위해 필요한 Apache , MySQL 와 PHP 를 포함한다. 그것들은 XAMPP 를 사용하여 구축된다. 자세한건 다음 문서를 보면된다. Complete install packages for Windows. 노트 : 이 패키지들의 인스톨러 프로그램은 몇몇 안티 바이러스 프로그램들로부터 실패 경고창을 유발한다고 알려져 있다. 이 패키지들은 바이러스가 없으니 안심하길 바란다. - 시스템 요구사항 최하 256 MB 램, 512 MB 램 (추천)160 MB free 빈공간의 ..
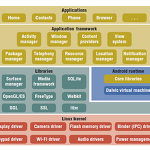 안드로이드 프로그래밍을 위한 기초
안드로이드 프로그래밍을 위한 기초
1. 안드로이드 구조 안드로이드 소프트웨어 스택 리눅스 커널 - 안드로이드는 리눅스를 사용하여 보안,메모리관리,프로세스 관리, 네트워크, 장치 드라이버 같은 시스템 서비스를 제공 - 커널은 하드웨어와 상위 레이어들 사이의 추상화 계층으로 동작한다. 안드로이드 런타임 - 안드로이드 런타임은 애플리케이션을 실행시키기 위한 최소한의 환경을 제공한다. - 자바의 코어 라이브러리와 달빅 가상머신으로 구성된다. - 안드로이드 애플리케이션은 리눅스의 하나의 프로세스로 실행되며, 각 프로세스 마다 자신만의 달빅가상머신을 가진다. - 여러개의 가상머신이 동시에 실행될수있으므로 달빅가상머신은 효율적으로 실행될수있도록 설계되었다. - 달빅가상머신은 레지스터 기반이며 자바 컴파일러에 의하여 컴파일된 클래스들을 .dex 형식으..
미니언어를 만들기위한 상황으로는 "로보트를 만들고 해당 로보트에게 "go 3 left 4" 라는 명령어를 주면 저 명령을 파싱해서 실행해야하는 순간""문서를 분석하기위해 "(love & like ) & baby " 문서에 저런 문자가 있으면 true 를 뱉어내는 , 감성분석할때 필요" "소켓통신할때 패킷으로 명령집합을 보내고, 받아서 해석해서 실행" " SQL 언어의 where 절 분석" 등등 자바나 C++같은 언어만큼 복잡한 기능이 필요없지만 많은 경우 필요할때가 있다..미니언어를 만들기위한 방법으로는 여러가지 방법이 있지만이 글에서는 스칼라언어의 컴비네터 파싱에 대해 간단히 알아본다. ( 언어 만드는것에 대한 깊이있는 내용은 나도 잘 모른다. 파싱만해도 굉장히 많은 알고리즘이 있다.) 컴비네이터 파싱..
출처 : http://nine8007.tistory.com/entry/%EA%B4%9C%EC%B0%AE%EC%9D%80-CSS-%ED%8C%A8%ED%84%B4-%EC%82%AC%EC%9D%B4%ED%8A%B8%EB%93%A4 이미지 패턴 사이트 : http://subtlepatterns.com/현재 387개의 패턴이 등록되어 있으며 Preview 버튼을 클릭하면 웹상에서 바로 적용된 모습을 확인해 볼 수 있습니다. 꽤 괜찮은 것들이 많이 있으니 한번 구경해 보세요.
출처 :http://nine8007.tistory.com/entry/%EA%B9%94%EB%81%94%ED%95%9C-%ED%8C%8C%EC%9B%8C%ED%8F%AC%EC%9D%B8%ED%8A%B8-%ED%85%9C%ED%94%8C%EB%A6%BF-%EB%AC%B4%EB%A3%8C-%EC%A0%9C%EA%B3%B5-%EC%82%AC%EC%9D%B4%ED%8A%B8 KINGSOFT Office왼쪽의 사이드바에 카테고리가 있어서 원하는 자료를 찾기 쉽습니다.오른쪽의 그림을 누르면 바로 다운로드 됩니다. 몇개의 자료는 다운로드가 안되더군요.아래의 그림들은 챠트나 다이아그램들의 템플릿을 한번 다운로드 받아본 것입니다. shOweet.com두번째는 showeet.com이라는 사이트인데 좀 느리기는 하지만 회사 ..
출처 : http://nine8007.tistory.com/275 사용분야 : 포토샵, 파워포인트, 엑셀, 웹페이지, 블로그 등 페이지의 집중도를 높여주는 곳 (특히 파워포인트에서는 깔끔한 비주얼 좋아요)아이콘이라고 해서 꼭 컴퓨터나 핸드폰의 바탕화면 아이콘만 사용한다는 편견은 버려주세요. 왜냐하면 아이콘의 크기가 큰것은 512 x 512 까지되는 것도 많기 때문입니다. 1. IconFinder 아이콘파인더는 세계에서 가장 유명하고 방대한 량의 아이콘을 보유 및 검색할 수 있는 최고의 엔진중에 하나이다. 이 포스트를 쓰고 있는 현재 약 38만 6천개의 아이콘중에서 검색한다. 무료 아이콘은 일단 키워드 검색으로 키워드를 넣고 엔터를 친후에 Free로 다시 필터링하면 된다.ICONFINDER 가기 2. Fi..