
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 그라파나
- play2 강좌
- 엔터프라이즈 블록체인
- Adapter 패턴
- 블록체인
- 파이썬 머신러닝
- 스칼라 동시성
- CORDA
- 하이퍼레저 패브릭
- Actor
- 스칼라
- 플레이프레임워크
- 파이썬 동시성
- 안드로이드 웹뷰
- 파이썬 데이터분석
- 이더리움
- Akka
- play 강좌
- Golang
- Play2
- 스위프트
- 스칼라 강좌
- Hyperledger fabric gossip protocol
- 하이브리드앱
- 주키퍼
- akka 강좌
- 파이썬
- Play2 로 웹 개발
- 파이썬 강좌
- hyperledger fabric
- Today
- Total
목록인터프리터 (4)
HAMA 블로그
미니언어를 만들기위한 상황으로는 "로보트를 만들고 해당 로보트에게 "go 3 left 4" 라는 명령어를 주면 저 명령을 파싱해서 실행해야하는 순간""문서를 분석하기위해 "(love & like ) & baby " 문서에 저런 문자가 있으면 true 를 뱉어내는 , 감성분석할때 필요" "소켓통신할때 패킷으로 명령집합을 보내고, 받아서 해석해서 실행" " SQL 언어의 where 절 분석" 등등 자바나 C++같은 언어만큼 복잡한 기능이 필요없지만 많은 경우 필요할때가 있다..미니언어를 만들기위한 방법으로는 여러가지 방법이 있지만이 글에서는 스칼라언어의 컴비네터 파싱에 대해 간단히 알아본다. ( 언어 만드는것에 대한 깊이있는 내용은 나도 잘 모른다. 파싱만해도 굉장히 많은 알고리즘이 있다.) 컴비네이터 파싱..
http://weizhishi.com/questions/86145/recursive-descent-vs-lexparseI think I understand (roughly) how recursive descent parsers (e.g. Scala's Parser Combinators) work: You parse the input string with one parser, and that parser calls other, smaller parsers for each "part" of the whole input, and so on, until you reach the low level parsers which directly generate the AST from fragments of the inp..
http://en.wikipedia.org/wiki/Recursive_descent_parser http://lara.epfl.ch/w/compilation:recursive_descent_parsing http://math.hws.edu/javanotes/c9/s5.html http://ag-kastens.uni-paderborn.de/lehre/material/uebi/parsdemo/recintro.html http://blogs.msdn.com/b/ericwhite/archive/2010/07/30/building-a-simple-recursive-descent-parser.aspx http://labun.com/fh/ma.pdf
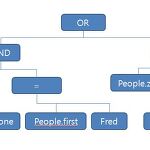 소형 SQL 인터프리터 만들기
소형 SQL 인터프리터 만들기
* 작성되는글은 Holub on Pattern 을 보고 정리한것입니다. 먼저 BNF statement ::= INSERT INTO INDENTIFIER [LP idList RP] VALUES LP exprList RP | CREATE DATABASE IDENTIFIER| CREATE TABLE IDENTIFIER LP declarations RP| DROP TABLE IDENTIFIER| BEGIN | WORK | TRAN[SACTION]]| COMMIT | WORK | TRAN[SACTION]]| ROLLBACK [WORK | TRAN[SACTION]]| DUMP| USE DATABASE IDENTIFIER| UPDATE IDENTIFIER SET IDENTIFIER EQUAL expr WHERE ex..