InfluxDB , Telegraf, Grafana 모니터링 설치 (2021년 8월기준)
* 해당 글은 리눅스 기준 입니다. (CentOS 7버전, Ubuntu18에서 잘됨)
InfluxDB 2.x 설치
(docs.influxdata.com/influxdb/v2.0/get-started/?t=Linux)
아래 2가지 방식 중에 패키지로 서비스로 시작하는것을 추천한다.
파일로 받아서 실행 하기)
- curl -s https://repos.influxdata.com/influxdb2.key | gpg --import -
- wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.4-linux-amd64.tar.gz
3. tar xvzf influxdb2-2.0.4-linux-amd64.tar.gz
4. cd influxdb2-2.0.4-linux-amd64
5. influxd 로 시작한다.
패키지로 인스톨 및 서비스시작하기 (arm64 or amd64 시스템에 맞게 변경해야함)
- RedHat & CentOS (amd 64-bit)
https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.4.x86_64.rpm
sudo yum localinstall influxdb2-2.0.4.x86_64.rpmsystemctl start influxdb
systemctl enable influxdb
systemctl status influxdb
- Ubuntu & Debian (amd 64-bit)
https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.4-amd64.deb
sudo dpkg -i influxdb2-2.0.4-amd64.deb
sudo service influxdb start
sudo service influxdb status
InfluxDB UI설정하기
최신 InfluxDB는 UI도 수려하게 지원한다. 따라서 UI를 통한 셋업방법을 알아보자.
1. localhost:8086 으로 접속하면 UI에 접근할수있다.
2. 아래 설정을 넣는다. (매우 중요하다.)
- Username 넣어준다. (예: hama)
- Password 넣어준다. (기억해두시라)
- Organization 이름 넣어준다. <-- 이전버전에는 없는 것이다.
- Bucket 이름 생성한다. <-- 이전버전에는 없는 것이다.
- Click Continue.
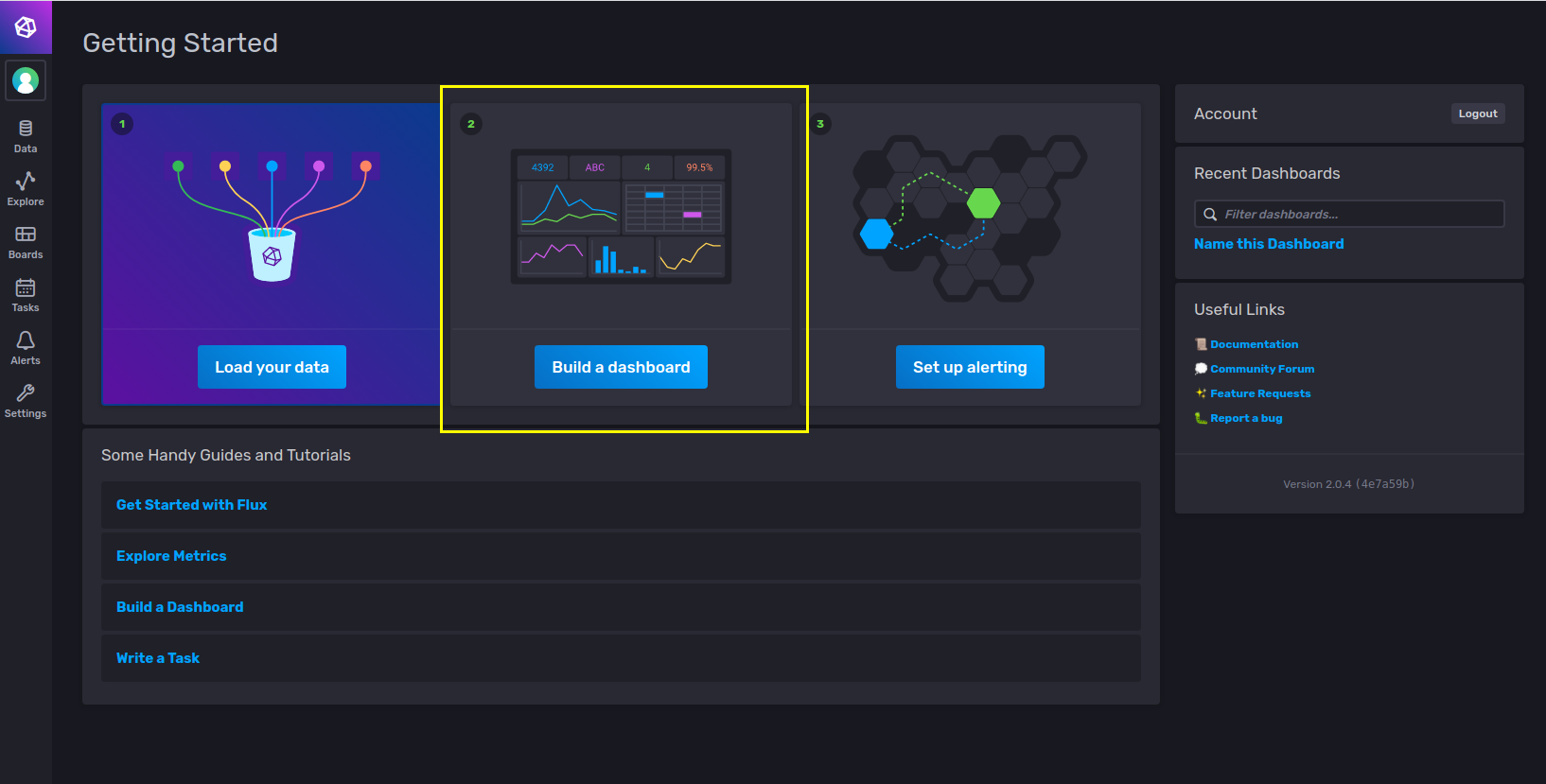
3. 메인 화면에서 Build a dashboard 를 선택한다.
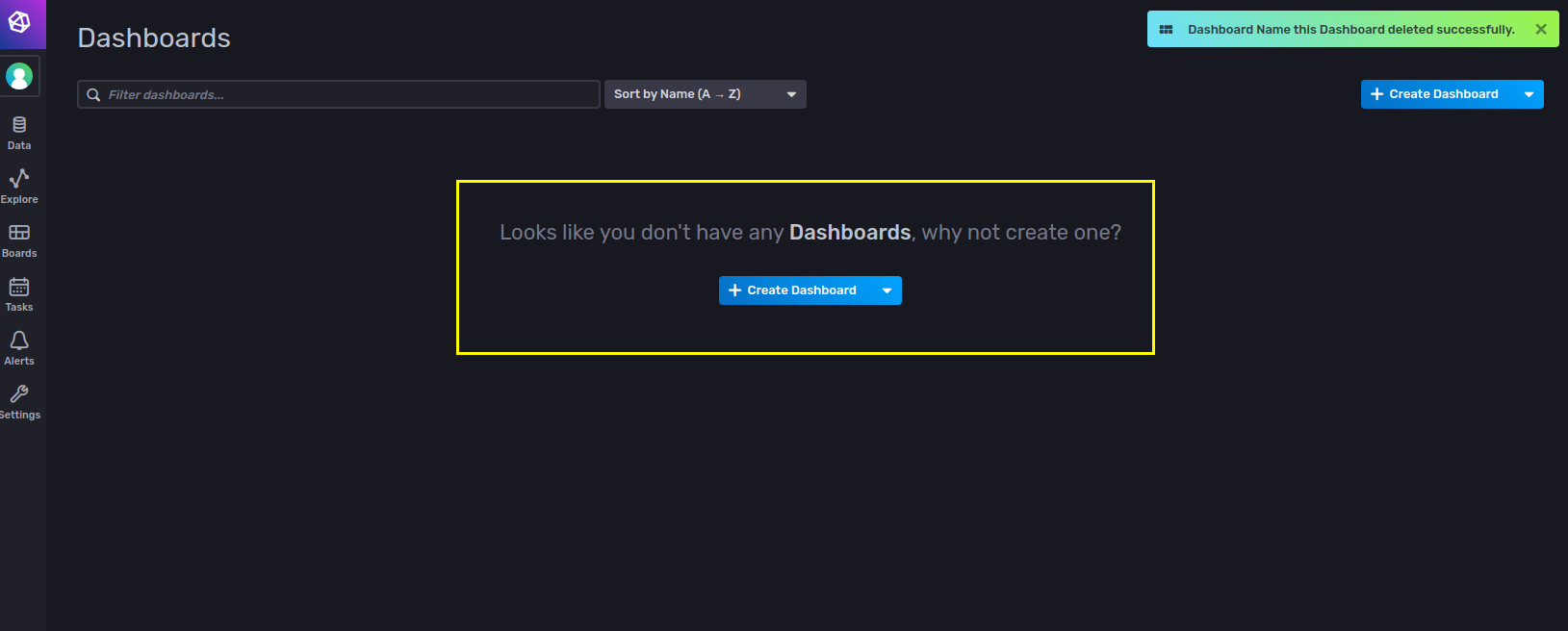
4. Create Dashboard 를 선택한다.

5. Add Cell 을 선택한다.
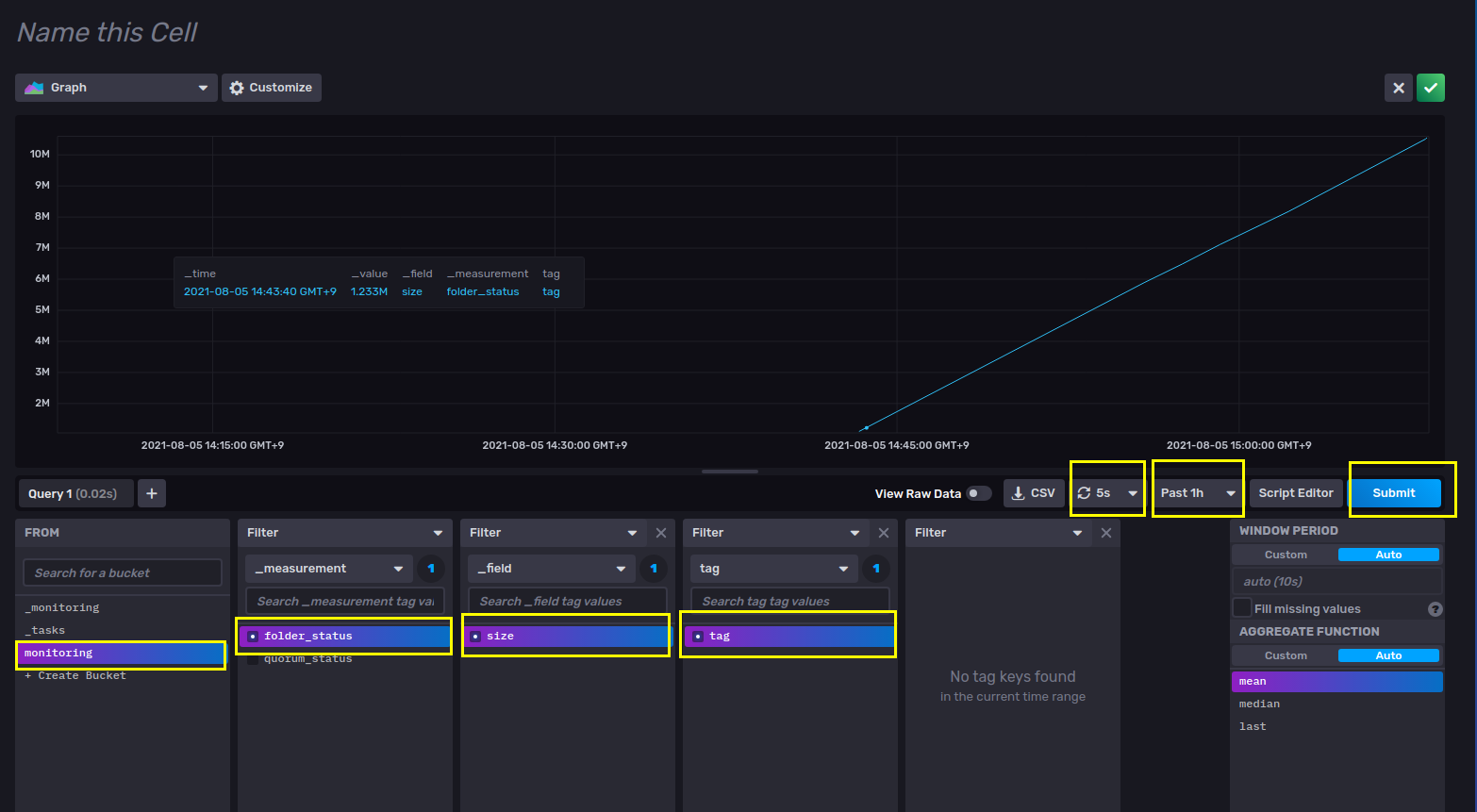
6.
- from (bukcet) : monitoirng 선택한다. 즉 bucket 이름이다
- filter (_measurement) : folder_status 를 선택한다. .
- filter (_field) : size를 선택한다.
- filter (tag) : tag를 선택한다.
- 5s refresh : 5초마다 화면을 갱신해준다
- past 1h : 과거 1시간 전 데이터 부터 보여준다
- Submit : 적용한다.
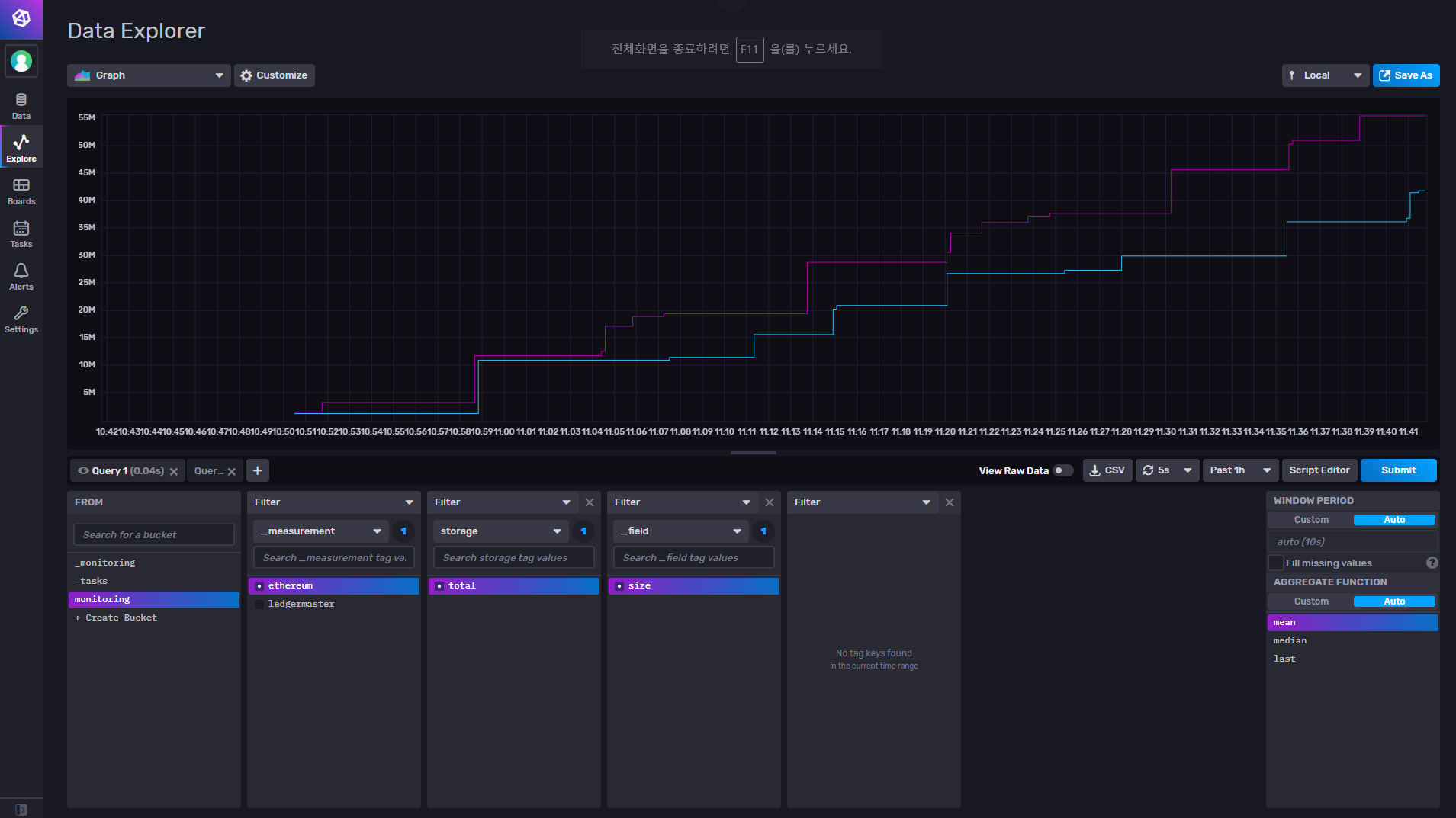
Influxdb의 ui를 통해 위와 같이 나오는 것을 볼 수 있다. (메뉴얼없어도 직관적으로 다룰 수 있을 것이다)
InfluxDB에 데이터 넣기
대략 아래와 같이 코딩하자. (참고 소스 : https://github.com/wowlsh93/monitoring)
module github.com/wowlsh93/monitoring
go 1.14
require (
....
github.com/influxdata/influxdb-client-go/v2 v2.2.2
)
- influxdb 클라이언트 의존성은 v2.2.2
//DBPATH: http://localhost:8086
//AUTHTOKEN: zYR-2G5BRmb5SDIkbKRUe2DXyon4rbXEzjoTwsSDHMUWeO3hTjasWBIGw8W7Dy_QxipDNWOj2g5MMD9le8-B3Q==
db := influxdb.Influxdb{
Client : influxdb2.NewClient(conf.DBPATH, conf.AUTHTOKEN),
}- influxdb를 접근하기위해서는 db 경로와 auth 토큰이 필요하다.
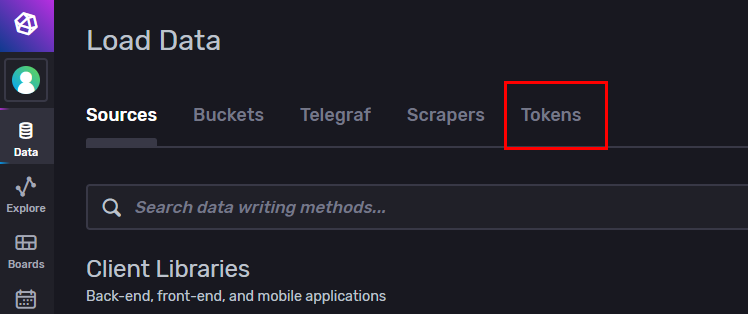
auth token 발급법은 docs.influxdata.com/influxdb/v2.0/security/tokens/create-token/ 링크에서 알수있다.
간략히 설명하면 UI에서 Data -> Tokens를 가면 발급받을 수 있다. (아래 빨간색 사각형)
package influxdb
import (
"context"
"github.com/influxdata/influxdb-client-go/v2"
"time"
)
type Influxdb struct {
Client influxdb2.Client
}
func (db* Influxdb) AddData(measurement string, curSize int64) {
writeAPI := db.Client.WriteAPIBlocking("opusm", "monitoring")
p := influxdb2.NewPointWithMeasurement(measurement).
AddTag("storage", "total").
AddField("size", curSize).
SetTime(time.Now())
writeAPI.WritePoint(context.Background(), p)
}
func (db* Influxdb) Close() {
db.Client.Close()
}- 위와 같이 influxdb에 값을 넣을 수 있다.
- "opusm" 은 조직이고
- "ledgermaster" 은 버켓이고 (참고로 이건 데이타베이스라고 생각하자.)
- Measurement 도 지정하자. (참고로 이건 테이블과 비슷하다고 보면 된다)
- Tag, Field 도 넣어주자 (참고로 Tag는 인덱싱되는 컬럼, Field는 그냥 컬럼들이라고 생각하자, 둘다 key,value 쌍이다)
- Field 값은 필드 값은 strings, floats, integers, boolean 타입을 가진다.
- 해당 timestamp에 field set, tag set 들이 구성된다. (key, value 를 합쳐서 set이라고 한다)
* tag 는 아래와 같이 사용된다.
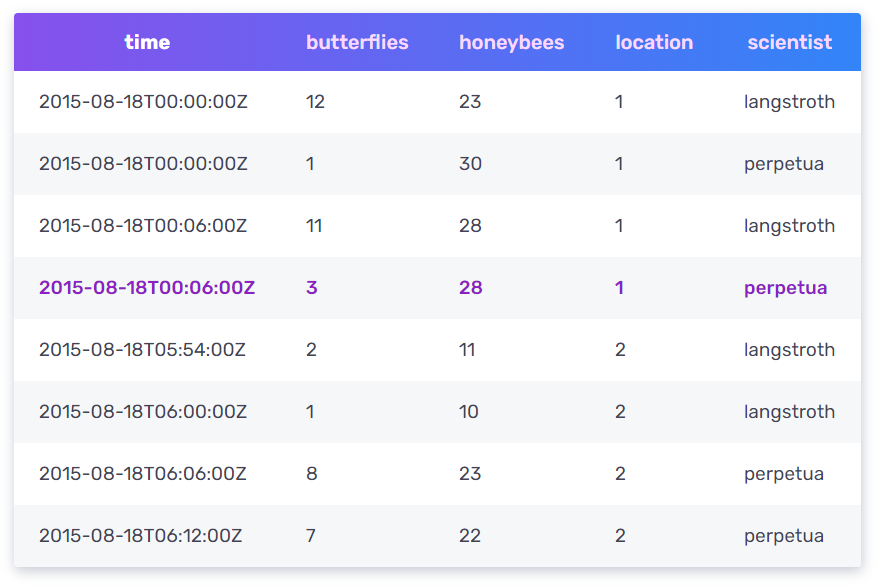
butterflies 와 honeybees의 갯수는 일반 필드이고, location 과 scientist는 tag인데 생각을 해보자!! 보통 우리는 과학자에 필터링을 걸 것어서 사용 할 것이다. scientist=perpetua 처럼 말이다. perpetua 과학자가 처리한 데이터만 골라서 보여주고 싶을 것이다. 이런 그룹짓고 싶은 필터링에 indexing을 거는 것이다 tag를 사용해서~~
* 포인트와 시리즈이라는 개념도 중요한데 시리즈에 대해 잘 이해가 안가는..
Telegraf 1.17 (influxdb2 용)
(docs.influxdata.com/telegraf/v1.17/introduction/getting-started/)
1. 설치하기
Ubuntu & Debian
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.17.3-1_amd64.deb sudo dpkg -i telegraf_1.17.3-1_amd64.deb
RedHat & CentOS
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.17.3-1.x86_64.rpm
sudo yum localinstall telegraf-1.17.3-1.x86_64.rpm
Linux Binaries (64-bit)
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.17.3_linux_amd64.tar.gz
tar xf telegraf-1.17.3_linux_amd64.tar.gz
2. 기본설정하기
2-1)
vi /etc/telegraf/telegraf.conf 에서
[[outputs.influxdb_v2]]
urls = ["$INFLUX_HOST"]
token = "$INFLUX_TOKEN"
organization = "$INFLUX_ORG"
bucket = "telegraf"
을 해주면 influxdb2로 출력해준다.
2-2))
telegraf -sample-config --input-filter cpu:mem --output-filter influxdb > telegraf.conf
cpu 사용량 및 메모리 사용량에 대한 메트릭을 읽게한다. 아래의 output출력으로 정보를 보낼 수 있다.
3. 시작하기
systemctl start telegraf <-- 시작하기
sudo systemctl status telegraf <-- 확인하기
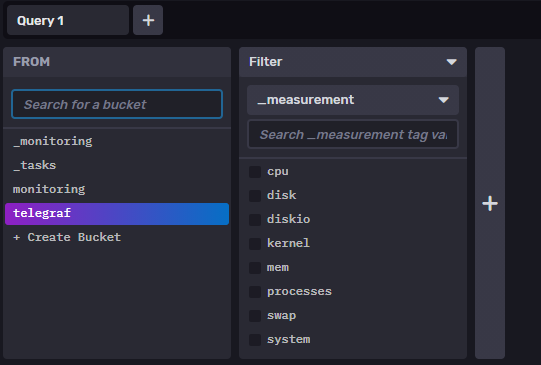
UI의 telegraf 버킷에 각종 system 값들이 들어온것을 볼 수 있다.
4. 특정폴더사이즈 감시
4-1)
#!/usr/bin/env bash
du -bs "${1}" | awk '{print "[ { \"bytes\": "$1", \"dudir\": \""$2"\" } ]";}'
를 metrics-exec_du.sh 이름으로 만든다.
4-2) 아래를 telegraf.conf파일에 추가한다.
[[inputs.exec]]
commands = [ "YOUR_PATH/metrics-exec_du.sh /var/lib/influxdb/data" ]
timeout = "10s"
name_override = "quorum-test"
name_suffix = ""
data_format = "json"
tag_keys = [ "dudir" ]
4-3) systemctl restart telegraf 로 다시 시작한다.
Grafana 8.0.6
1. 설치하기 grafana.com/grafana/download
Red Hat, CentOS, RHEL, and Fedora(64 Bit)
wget https://dl.grafana.com/oss/release/grafana-8.0.6-1.x86_64.rpm
sudo yum install grafana-8.0.6-1.x86_64.rpm
Ubuntu and Debian(64 Bit)
sudo apt-get install -y adduser libfontconfig1
wget https://dl.grafana.com/oss/release/grafana_8.0.6_amd64.deb
sudo dpkg -i grafana_8.0.6_amd64.deb
2. 실행하기 grafana.com/docs/grafana/latest/installation/rpm/#2-start-the-server
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl status grafana-server
sudo systemctl enable grafana-server
* 방화벽 해제 (centos에서 외부에서 3000포트로 접근하려는데 방화벽이 실행중이라면)
sudo systemctl stop firewalld
3. Grafana UI 다루기 grafana.com/docs/grafana/latest/getting-started/getting-started/
브라우저에서 다음 주소로 Grafana UI 에 들어간다. => http://localhost:3000/
admin/admin 으로 들어간후에 비밀번호 바꿔준다.

메인화면은 위와 같다.
4. Data Source 추가하기

Data sources선택
InfluxDB 선택
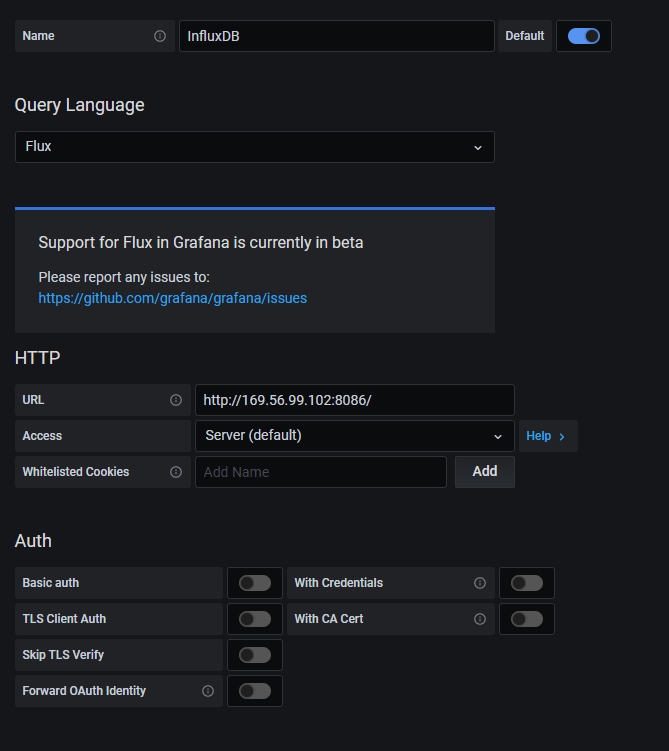
* 이전버전 InfluxDB 데이타소스 방식과 매우 많이 달라졌다. (4버전대가 편했는데....)
- 이름은 아무거나 만들어주고
- 여기선 Query Language 를 Flux로 한다. 이게 새로 추가된 방식이다. (InfluxDB 2.x대에는 이걸 써야한다)
- HTTP에 URL을 http://your ip address:8086
나머지는 건드리지 않았다. (혹시 Basic auth 켜있으면 꺼준다)

- 조직은 influxdb 설정에서 만든것을 넣어준다.
- 토큰은 influxdb 에서 만든 auth token 문자열을 넣어준다.
- 버킷에는 influxdb 설정에서 만든 것을 넣어준다.
나머지는 건드리지 않았다.
Save& Test를 해주며 끝마친다.
5. 데시보드 추가하기

Dashboard선택
일단 Add an empty panel 을 선택한다.
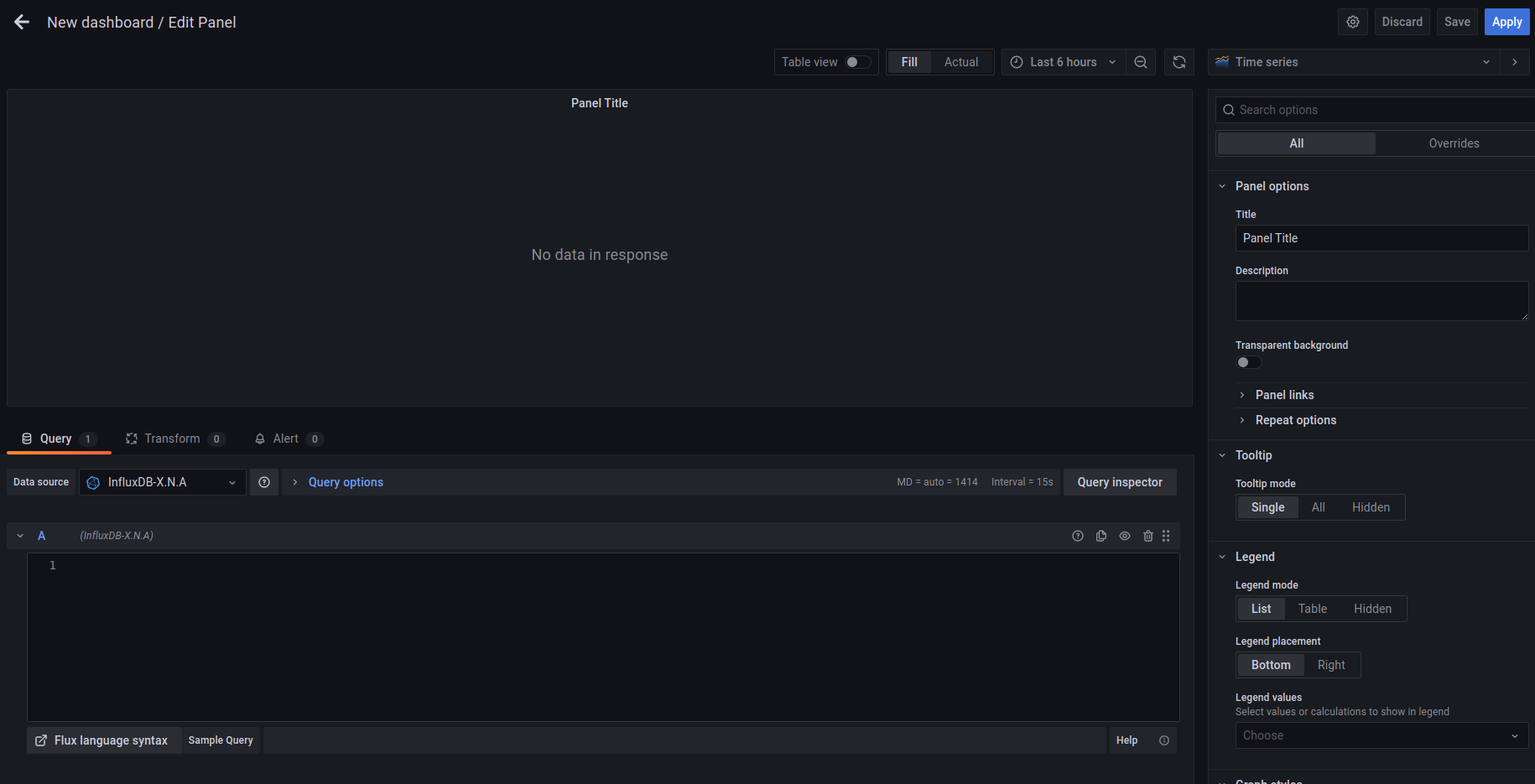
이전 버전(4.x대 이전)과는 굉장히 많은 차이가 있다.
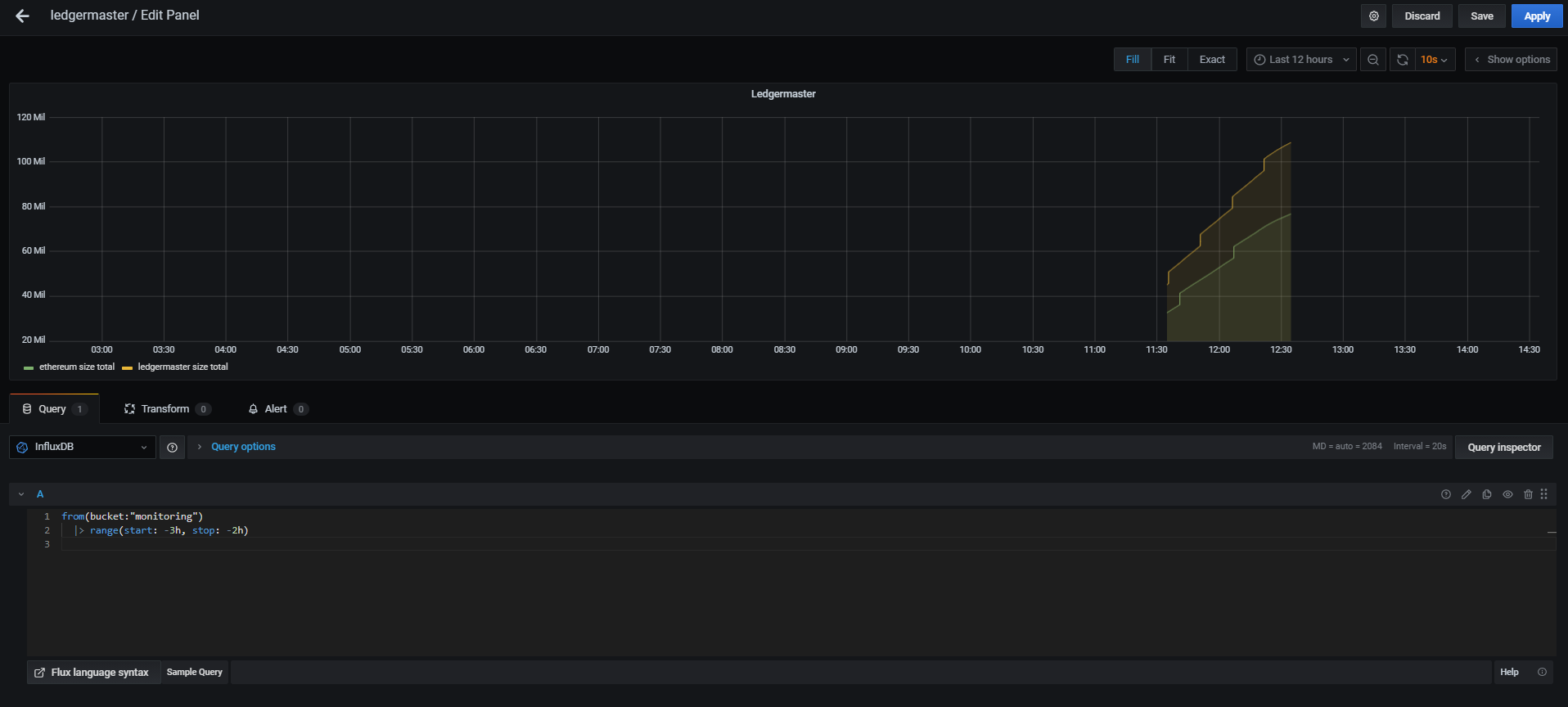
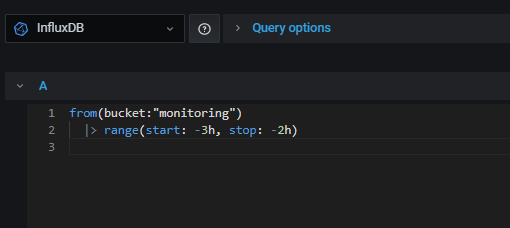
- Flux language syntax 를 이용하여 쿼리하여 데이터를 보여준다.
- bucket 으로 부터 3시간 이전 데이터부터 2시간 이전데이터까지를 보여준다.
- 새로 만들어진 Flux 스크립트 기반으로 모니터링 환경을 꾸미려면 관련 학습이 선행되어야 할 것 같다.
Getting start with Flux => https://docs.influxdata.com/influxdb/v2.0/query-data/get-started/
이로써 기초적인 설치와 세팅이 끝났다.
6. Flux 예제

- example-bucket 이란 이름의 버킷으로 부터 데이터를 가져온다.
- 1시간 전 부터 시작하는 데이터를 가져 온다
- measurement 는 "cpu" 를 가져온다.
- tag 키가 cpu이고 tag 밸류가 "cpu-total" 인 포인트만 가져온다.
- 1분간의 데이터를 평균(mean)하여 가져온다. (즉 그래프에는 1시간 전부터 시작하여 1분당 한개의 값만 나올 것이다.)