우리가 해야할 것: 컨베이어 정션 웹 서비스
컨테이너가 컨베이어 교차로상에서 어디로 나가야 할지를 알려주는 웹서비스에 대해 구상해 봅니다.

이 웹 서비스는 컨테이너가 교차점(Junction) 앞에서 스캔 될 때마다 호출될 하나의 엔드 포인트를 정의 합니다. 엔드 포인트는 대상 컨베이어의 ID를 리턴해야 하며, 컨테이너는 하드웨어에 의해 리턴 받은 목표 컨베이어로 밀려나게 됩니다.
GET /junctions/<junctionId>/decisionForContainer/<containerId>
를 호출하면 아래처럼 컨베이어 ID 가 리턴됩니다.
{
"targetConveyor": "<conveyorId>"
}구현을 시작하기 전에 몇 가지 가정을 하겠습니다.
- id 만 가지고 있는 단순한 Container 객체를 사용한다 (persistence layer는 나중에 추가 될 수 있다)
- id 만 가지고 있는 단순한 Junction 객체를 사용한다. (같은 이야기)
- 비즈니스 로직은 이미 whereShouldContainerGo 함수에 정의되어 있다. 매개 변수 중 하나로 주어질 교차점 상에서 해당 Container가 이동해야 할 컨베이어에 대한 결정을 반환한다. (즉 교차점과 컨테이너를 주고 목적 컨베이어를 받는다) 이 함수에 대한 호출에는 약 5-10ms가 소요된다.
비즈니스 로직 함수를 호출 할 앞 단의 HTTP 서비스를 구현해야 합니다.
이 글에서의 촛점은 다양한 기능이 아니라 (위의 단순한 가정들), 성능과 확장성이라는 것을 명심해 두십시요.
유일한 기능 요구 사항은 각 교차점에서 스캔된 컨테이너가 어떤 컨베이어로 이동해야 할 지에 대한 결정을 내려야한다는 것입니다.
akka-sharding-example repository on GitHub. 저장소를 통해 이 글을 이해하는데 도움을 받을 수 있을 것이며,
이 블로그 게시물의 각 단계에 상응되는 코드들이 있기 때문에 보다 쉽게 이해 하고 응용 할 수 있을 것 입니다.
우리는 Akka 를 사용할 것입니다.
우리는 평범한 Akka를 사용할 것이고 추가 확장은 없으며 특히 아직 클러스터링에 대한 고려는 없습니다. 하나의 JVM에서 실행되는 간단한 애플리케이션으로 시작하며, 확장성에 대해 초반에 생각하지 않았더라도 나중에 그것을 추가하는 것이 생각보다 쉽다는 것을 보여주고 싶습니다.
Step 0: 도메인 및 내부 API 정의
이제 어떤 언어로 컴포넌트(actor) 가 소통하고 어떻게 도메인을 모델링할 것인지에 대해 정의 할 것인데요.
우리는 Scala 언어의 케이스 클래스를 사용하여 쉽게 표현 할 수 있었습니다.
object Domain {
case class Junction(id: Int)
case class Container(id: Int)
}도메인 객체는 두 개뿐이며, 하나는 교차점을 나타내고 다른 하나는 컨테이너를 나타냅니다.
둘 다 불변의 id 만 속성으로 갖게 됩니다.
우리의 서비스는 어떤 JSON 데이터도 받지 않을 것이고, 그저 JSON 객체를 반환 할 것입니다.
Go (targetConveyor) 동반자 객체에 정의된 암시적 기본 변환으로 인해 자동으로 JSON으로 마샬링 될 것입니다.
object Messages {
case class Go(targetConveyor: String)
object Go {
implicit val goJson = jsonFormat1(Go.apply)
}
}Step 1: Creating REST Interface layer
이제 진짜를 코딩 할 시간이 왔습니다.
HTTP 서비스를 구현하기 위해 우리는 spray-json과 함께 spray-http를 사용할 것입니다.(akka-http 를 이용한 소스도 깃헙에 준비되어 있습니다.) 우리의 서비스는 하나의 엔드 포인트만 정의할 것이며, 전달된 매개 변수를 가지고 비즈니스 로직 함수를 호출한 후에, Go 객체로 래핑하여 결과를 반환할 것 입니다.
class RestInterface(exposedPort: Int) extends Actor with HttpServiceBase with ActorLogging {
val route: Route = {
path("junctions" / IntNumber / "decisionForContainer" / IntNumber) { (junctionId, containerId) =>
get {
complete {
log.info(s"Request for junction $junctionId and container $containerId")
val junction = Junction(junctionId)
val container = Container(containerId)
val decision = Decisions.whereShouldContainerGo(junction, container)
Go(decision)
}
}
}
}
def receive = runRoute(route)
implicit val system = context.system
IO(Http) ! Http.Bind(self, interface = "0.0.0.0", port = exposedPort)
}[역주] 스칼라 문법 - "함수 호출에 관한 썰~"
스칼라에서는 함수호출시 () 대신 {} 중괄호를 사용 할 수 있다. 단 !!! 인자가 하나일 경우 !!
def formatEuro (amt : Double) = {.......} <-- 와 같은 Double 형의 매개변수 하나를 받는 함수가 있을 시
formatEuro { val rate = 1.32; 0.235 + 0.7123 + rate * 5.32 } <-- 이렇게 호출 할 수 있는데, {} 블럭 안에서 평가된 rate 가 매개변수로 들어가게 된다.
println ("Hello World") 대신해서 println { "Hello World" } 를 사용 할 수 있다는 의미이다.
스칼라에서 이렇게 한 이유는 프로그래머가 중괄호{} 내부에서 좀 복잡한 함수 리터럴을 직접 사용하도록 하기 위해서인데, 이렇게 작성한 메소드는 호출 시 좀 더 제어 추상화 구문과 비슷해진다. 좀 더 수준높은 예제를 들어 보면
def withPrintWriter(file: File, op: PrintWriter => Unit ) {
val writer = new PrintWriter(file)
try {
op (writer)
} finally {
writer.close()
}
}
이런 함수를 호출 할 때는
withPrintWriter ( new File ("date.txt") , writer => writer.println(new java.util.Date) )
이렇게 호출 하며, 여기서는 인자가 2개이기 때문에 { } 를 사용할 수 없다. 하지만 !!!!
def withPrintWriter(file: File) (op: PrintWriter => Unit ) { ...
}
이러한 함수라면 {} 를 사용 할 수 있다.
val file = new File("date.txt")
withPrintWriter (file) { writer => writer.println(new java.util.Date) }
왜 이게 되냐면 커링을 통해서 file 을 매개변수로 먼저 넣어진 새로운 함수가 생겨졌고,
그 새로운 함수는 매개변수 하나를 필요로 하는 함수이기 때문이다.!!
보통 (변수,함수) 매개변수 조합일 때 많이 사용된다.
def foldLeft[B](z: B)(op: (B, A) => B): B = {
var result = z
this foreach (x => result = op(result, x))
result
}
Vector(1, 2, 3).foldLeft(Vector[Int]()) { (is, i) =>
is :+ i * i
}
(curry vs partially applying 이라는 헥깔림 주제도 있다)
HTTP 요청을 처리 할 액터를 정의했습니다. (역주: Akka 를 이용하여 간단히 Rest Api 서버를 만들 수 있습니다.)
이 액터 내에서 중첩된 지시문(Directives)들로 생성된 route 를 만들었습니다
- path 지시문은 지정된 PathMatcher를 HTTP 요청 경로에 적용하고 매칭이 성공하면 중첩 경로에 요청을 전달합니다. 또한 전달된 Path에서 junctionId 및 containerId 라는 두 개의 값을 추출합니다.
- get 지시문은 HTTP GET 메서드 요청만 중첩 된 경로로 전달되도록 합니다.
- complete 지시문은 마샬러블 객체를 받아 들여 HTTP 응답으로 반환합니다. 이 경우 블럭킹을 하지 않고 비동기적으로 Future [Go] 를 내 개체로 반환합니다. 이 Future가 완료되면 실제 응답이 반환 (역주: 이 역할 전용의 쓰레드풀이 따로 있음. Scala Future 이해하기) 되는 식입니다.
지금까지의 것만으로 우리는 첫 번째 테스트를 실행하는 데 필요한 거의 모든 것을 갖추고 있습니다.
더 만들어야 할 유일한 것은 응용 프로그램의 진입점입니다. (extends App 을 통하여 maiin 감춰짐)
object SingleNodeApp extends App {
implicit val system = ActorSystem("sorter")
system.actorOf(RestInterface.props(8080))
}RestInterface 액터를 실행하고 있습니다. 8080 포트를 오픈했군요
이 애플리케이션을 실행하고 어떻게 작동하는지 살펴 보겠습니다.
± % http localhost:8080/junctions/2/decisionForContainer/3
HTTP/1.1 200 OK
Content-Length: 36
Content-Type: application/json; charset=UTF-8
Date: Sat, 10 Oct 2015 23:18:12 GMT
Server: spray-can/1.3.3
{
"targetConveyor": "CVR_2_9288"
}교차로#2 에서 컨테이너#3를 스캔 한 후 , 컨테이너#3를 컨베이어 CVR_2_9288 로 밀어 넣기로 결정했군요.
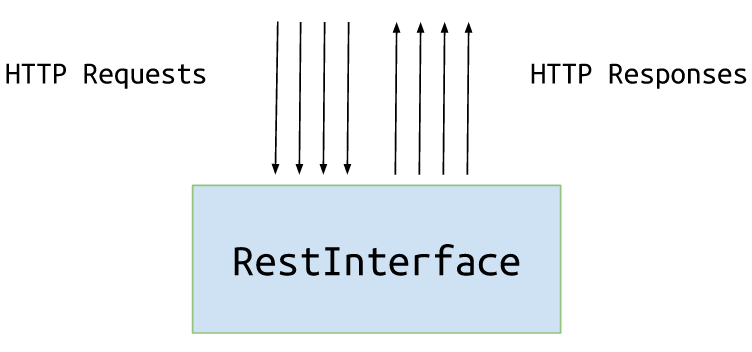
현재 아키텍처는 다음과 같습니다.
Performance testing
우리의 웹 서비스에 대해 10000건의 호출을 시뮬레이션 하여 5개의 교차점에 대한 결정을 확인해 봅시다. 우리는 성능 검사도구로 ab (ApacheBench)와 parallel (GNU Parallel)을 사용할 것입니다. 각 교차점에 대해 호출 시퀀스(ab 사용)를 시뮬레이트합니다. 병렬 처리는 웹 서비스 수준에서 시작할 것입니다. 5개의 다른 교차점에 대해 병렬 호출을 수행하기 위해 Parallel 을 사용할 것입니다.
성능 평가에 대한 노트
이 섹션에 표시된 숫자는 컴퓨터, OS, 실행중인 응용 프로그램, 네트워크 등에 따라 다를 수 있지만 이 게시물의 목적에 는 충분합니다.
Akka 에 대한 성능 제약
테스트가 의미가 있기 위해서는 Akka를 약간 제한해야 합니다. 저는 4코어 프로세서를 사용하고 있지만 실행중인 각 액터 시스템에 대해 기본 MessageDispatcher의 병렬 처리를 2로 제한 할 것입니다. 이렇게 하면 자원 확보에 어려움을 겪고 있는 서비스를 시뮬레이션 할 수 있을 것 입니다.
actor {
provider = "akka.cluster.ClusterActorRefProvider"
# capping default-dispatcher for demonstration purposes
default-dispatcher {
fork-join-executor {
# Max number of threads to cap factor-based parallelism number to
parallelism-max = 2
}
}
}첫번째 구현물을 테스팅 해 봅시다.
이제 우리가 만든 것을 시험 해 볼 시간입니다.
URLs.txt:
http://127.0.0.1:8080/junctions/1/decisionForContainer/1
http://127.0.0.1:8080/junctions/2/decisionForContainer/4
http://127.0.0.1:8080/junctions/3/decisionForContainer/5
http://127.0.0.1:8080/junctions/4/decisionForContainer/2
http://127.0.0.1:8080/junctions/5/decisionForContainer/7± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 34.78 [#/sec] (mean)
Requests per second: 34.22 [#/sec] (mean)
Requests per second: 33.77 [#/sec] (mean)
Requests per second: 33.82 [#/sec] (mean)
Requests per second: 33.98 [#/sec] (mean)우리는 5 개의 URL (각 교차점에 하나씩)을 병렬로 호출하도록 정의했으며 각각의 URL은 다음과 같습니다.
- 2000 번 호출(-n 2000),
- 해당 시간 당 많이 야 하나 (-c 1),
- keep-alive 사용 (-k) (역주: TCP/IP 에서의 KeepAlive 와 HTTP 에서의 KeepAlive 는 다릅니다.
여기서는 당연히 ab 가 HTTP 성능 도구이므로 HTTP KeepAlive 를 말합니다.)
우리는 초당 요청수(RPS,TPS) 에만 관심이 있습니다. 보시다시피, 우리 서비스의 처리량은 초당 약 34건입니다.
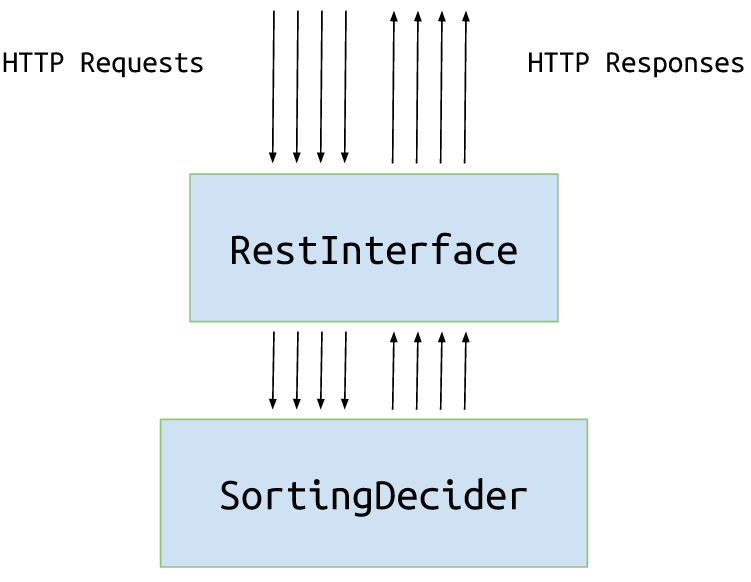
교차점 하나당 하나의 액터를 도입하여 관점을 바꾸어 봅시다. (현재는 액터 하나가 모든 교차점의 요청 처리)
Step 2: 교차점당 하나의 액터
현재는 모든 교차점에 대해 순차적 (역주: 동기적) 으로 처리하는 하나의 액터 (= 스레드 하나) 만 있습니다만, 각 교차점들에 대한 요청을 병렬(역주: 비동기적)로 처리함으로써 더 성능을 높일 수 있겠다는 생각을 할 수 있을 것입니다. (독립적이기 때문에).
먼저 Messages에 새 메시지를 추가하겠습니다.
object Messages {
case class WhereShouldIGo(junction: Junction, container: Container)
// ...
}WhereShouldIGo 메시지는 해당 메세지에 대한 처리를 담당하는 액터에게 전송 될 것입니다.
decider 액터는 매우 간단합니다. whereShouldIGo 메시지를 수신하고 whereShouldContainerGo 함수를 호출하여 얻은 정보를 Go로 응답 (역주: SortingDecider 액터에게 메세지를 보낸 액터에게 되돌림) 할 수 있어야 합니다.
class SortingDecider extends Actor with ActorLogging {
def receive: Receive = {
case WhereShouldIGo(junction, container) => {
val targetConveyor = Decisions.whereShouldContainerGo(junction, container)
sender ! Go(targetConveyor)
}
}
}이제 우리는 RestInterface 를 수정하여 하나의 decider 액터를 의존성에 추가하고, 의사 결정이 필요할 때 마다 이를 사용 할 것 입니다. (역주: ask 는 요청한 후 Future 로 값을 되돌려 받겠다는 의미이고, tell 은 보내기만 하는 함수이다)
class RestInterface(decider: ActorRef, exposedPort: Int) extends Actor with HttpServiceBase with ActorLogging {
val route: Route = {
path("junctions" / IntNumber / "decisionForContainer" / IntNumber) { (junctionId, containerId) =>
get {
complete {
log.info(s"Request for junction $junctionId and container $containerId")
val junction = Junction(junctionId)
val container = Container(containerId)
decider.ask(WhereShouldIGo(junction, container))(5 seconds).mapTo[Go]
}
}
}
}
// ...
}생성 단계에서 이 액터를 RestInterface에 전달합시다.
object SingleNodeApp extends App {
implicit val system = ActorSystem("sorter")
val decider = system.actorOf(Props[SortingDecider])
system.actorOf(Props(classOf[RestInterface], decider, 8080))
}단지 함수 호출을 감싸기 위해(역주: 함수호출하는것에서 액터 호출하는 것으로 바꾼것) 액터를 도입함으로써 얻은 것은 무엇일까요? 확인 해 봅시다.
± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 34.49 [#/sec] (mean)
Requests per second: 34.49 [#/sec] (mean)
Requests per second: 34.49 [#/sec] (mean)
Requests per second: 34.50 [#/sec] (mean)
Requests per second: 34.52 [#/sec] (mean).엥? 거의 똑같군요. 우리 코드는 여전히 순차적이며 또 다른 추상화 레이어를 추가하는 복잡함만 껴얹었을 뿐입니다.
(역주: 당연합니다. 처리를 위임한 액터도 시퀄셜 하게 작동하니까요~ )
음 낙심하지 마세요. 아직 끝나지 않았습니다~ 계속 봅시다.
Step 3: 교차점당 하나의 액터 + 라우팅
진짜 병렬을 하게 하기 위해 우리는 추가적으로 또 다른 레이어를 만들어야 할 거 같습니다. 그 액터는
SortingDeciders교차점과 프록시 WhereShouldIGo 메시지를 올바른게 처리할 것이며, 이것을 통해 우리 시스템이 의사 결정을 병렬로 하게 될 것입니다.
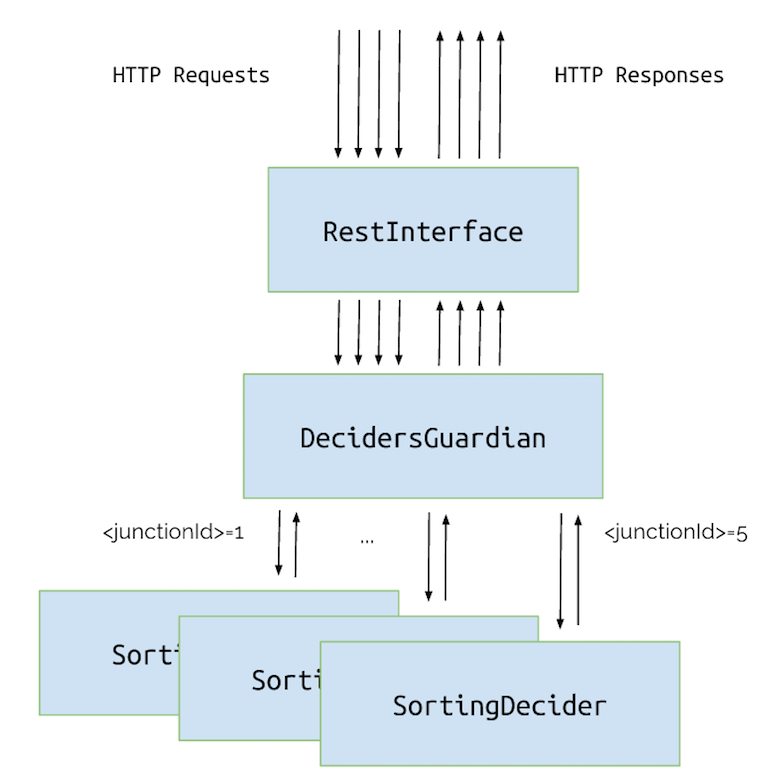
새로운 영웅인 DecidersGuardian 을 소개합니다.
class DecidersGuardian extends Actor {
def receive = {
case m: WhereShouldIGo =>
val name = s"J${m.junction.id}"
val actor = context.child(name) getOrElse context.actorOf(Props[SortingDecider], name)
actor forward m
}
}먼저 DecidersGuardian 액터를 RestInterface에 대한 의존성으로 추가합시다 :
object SingleNodeApp extends App {
implicit val system = ActorSystem("sorter")
val decider = system.actorOf(Props[DecidersGuardian])
system.actorOf(Props(classOf[RestInterface], decider, 8080))
}지금 RestInterface 가 서로 다른 교차점에 대해 2개의 메시지를 받으면 두 개의 다른 액터로 메시지를 전달하고 병렬로 의사 결정을 할 수 있게 됩니다. (역주: 이전에는 하나의 액터로 요청(ask)했었지요? 여기서는 여러 액터로 전달(foward) 합니다.) 이제 우리는 상당한 개선을 기대해 볼 수 있을 것 입니다.
± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 67.36 [#/sec] (mean)
Requests per second: 69.03 [#/sec] (mean)
Requests per second: 67.75 [#/sec] (mean)
Requests per second: 66.88 [#/sec] (mean)
Requests per second: 66.28 [#/sec] (mean)Scalability testing
지금까지 우리는 서비스의 성능에 대해서만 관심을 가졌었는데요. 아시다시피 성능이란 시간 이라는 단어로써 얼마나
빠른지를 보여줍니다. 지금까지 사용해온 "초당(시간당) 요청 수"가 좋은 예입니다. 그럼 성능과 확장성의 차이점은 무엇일까요?
시스템의 확장성은 더 많은 자원을 추가하는 것이 성능에 어떻게 영향을 미치는지에 관한 것입니다.
예 : 리소스를 두 배로 늘림으로써 처리량을 배가시키는 것은 선형 확장성입니다.
이 예에서는 더 많은 CPU를 추가 할 때 강력한 Akka 및 액터 모델 덕분에 확장성이 자동적으로 조정 될 수 있었습니다.이 방법을 스케일 업이라고합니다. (역주: CPU 를 더 추가하면 교차점 만큼 액터가 늘어나면도 서로 간섭을 최소화 함)
스케일 아웃, 즉 성능을 향상시키기 위해 더 많은 컴퓨터를 추가하는 것은 어떨까요?
Step 4: 웹서비스를 규모 확장성 있게 만들기
간단히 생각하면 우리는 더 많은 컴퓨터 (또는 JVM)를 추가하고 응용 프로그램을 따로 배포한 후 각각 실행하여 확장 할 수 있습니다. 그런 다음 요청에 따라 특정 컴퓨터로 트래픽을 수동으로 전달할 수 있을 것 입니다. (역주: 라운드 로빈으로 하든, 12345 교차점은 A 서버, 678910 교차점은 B 서버로 가게 하든 앞단에서 분배처리. 소프트웨어 LB)
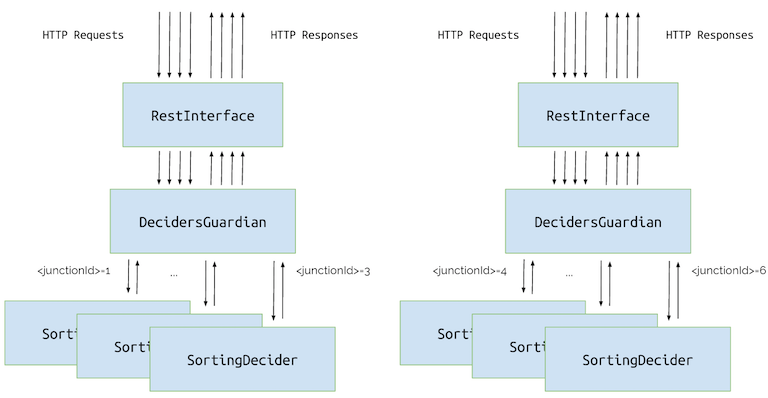
이 기법을 수동 스케일 아웃이라고합니다. 이 방법에는 몇 가지 단점이 있는데요. 로드밸런서에 비즈니스 로직을 유지해야 하며, 새로운 교차점 또는 컴퓨터를 추가 할 때마다 전체 설정을 조정해야 할 수 있습니다.
정말 다행히도 우리는 이러한 모든 작업을 수동으로 만들 필요가 없습니다. 대신, Akka Cluster extension을 사용 하면 됩니다. 우리는 SortingDecider 를 Sharded (역주: 여러 서버로 자동 분배) 할 것이구요. 이 액터의 인스턴스는 요청의 junction ID를 기반으로 자동으로 생성 될 것입니다. 우리는 두 개의 애플리케이션 인스턴스 (두 개의 노드)를 실행 할 것이며 그들은 서로를 자동으로 엮어서 Akka Cluster를 형성 할 것입니다. 클러스터의 모든 노드는 Sharding Extension이 SortingDecider 액터를 만들고 마이그레이션 하는 데 사용될 것입니다. 우리는 노드를 별다른 신경을 쓰지 않고 추가하고 제거 할 수 있으며, Akka는 자동으로 추가된 자원을 사용할 것입니다. 샤딩을 추가하기 위해 기존 코드를 변경할 필요는 없습니다. 또한 모든 책임은 Akka의 ShardRegion으로 마이그레이션되므로 이전에 우리가 만든 DecidersGuardian 은 필요하지 않습니다.
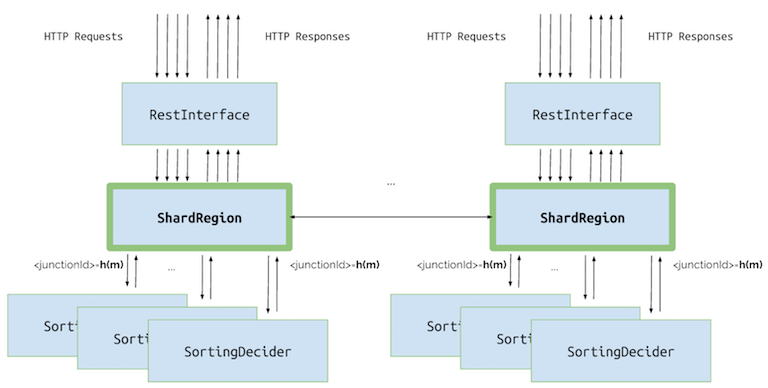
SortingDecider를 샤드하기 위해 해야 것은 단지 두 단계 입니다.
첫 번째 단계는 props, shardName 및 두 개의 "해시 함수"를 정의하는 동반자 객체를 만드는 것입니다.
extractShardId- (역주: 간단히 어느 서버로 갈 것인가) 이 함수는 수신 메시지를 기반으로 샤드 ID를 정의합니다. 샤드는 우리 액터의 집합일 뿐입니다. 그러한 세트는 하나의 노드에만 존재할 수 있으며 Akka는 사용 가능한 각 노드에서 비슷한 수의 샤드를 갖기 위해 시도합니다. 그래서,이 함수를 정의하는 것만으로, 어플리케이션이 지원하는 샤드의 수를 제어 할 수 있습니다. 여기서는 2 개의 샤드 만 지원합니다 (아래 코드 참조).extractEntityId- (역주: 어느 교차점 액터로 갈 것인가) 이 함수는 이 메시지를 처리 할 액터의 고유 식별자인 엔티티 ID를 정의합니다. Akka는 우리가 정의한 Props을 바탕으로 그 액터를 자동으로 만듭니다.
두 함수는 ShardRegion 이 메시지를 받을 때마다 호출됩니다. 먼저 extractShardId 함수가 호출되고 샤드 id를 반환합니다. Akka는 이것이 어느 노드에 보관되어 있는지 확인합니다. 이것이 다른 노드 인 경우 메시지는 이 쪽에서 추가 작업 없이 다른 노드로 전달됩니다. 이것이 이 노드에서 처리해야할 것이라면 extractEntityId 함수가 평가되고 특정 액터의 식별자인 엔티티ID를 반환합니다. 메시지는 액터로 전달되어 거기에서 처리되며 액터가 존재하지 않으면 자동으로 생성됩니다. 우리의 경우에는 교차점 (junction ) 마다 하나의 액터가 있으므로 extractEntityId 함수는 junction ID 만 리턴합니다.
이제 코드를 봅시다.
object SortingDecider {
def props = Props[SortingDecider]
def shardName = "sortingDecider"
val extractShardId: ExtractShardId = {
case WhereShouldIGo(junction, _) =>
(junction.id % 2).toString
}
val extractEntityId: ExtractEntityId = {
case m: WhereShouldIGo =>
(m.junction.id.toString, m)
}
}
class SortingDecider extends Actor {
// ...
}두 번째 단계는 정의된 SortingDecider컴패니언 객체를 기반으로 샤딩을 설정할 새로운 App을 정의하는 것입니다. 우리는 RestInterface를 포함하여 우리가 만든 다른 모든 액터를 재사용 할 것입니다.
object ShardedApp extends App {
val config = ConfigFactory.load("sharded")
val system = ActorSystem(config getString "clustering.cluster.name", config)
ClusterSharding(system).start(
typeName = SortingDecider.shardName,
entityProps = SortingDecider.props,
settings = ClusterShardingSettings(system),
extractShardId = SortingDecider.extractShardId,
extractEntityId = SortingDecider.extractEntityId)
val decider = ClusterSharding(system).shardRegion(SortingDecider.shardName)
system.actorOf(Props(classOf[RestInterface], decider, config getInt "application.exposed-port"))
}노드 한개 실행
하나의 노드만 실행 해 봅시다. 성능 테스트의 결과는 수동 솔루션과 동일해야 합니다.
java -jar target/SortingDecider-1.0-SNAPSHOT-uber.jar± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 68.39 [#/sec] (mean)
Requests per second: 66.30 [#/sec] (mean)
Requests per second: 65.99 [#/sec] (mean)
Requests per second: 64.86 [#/sec] (mean)
Requests per second: 64.54 [#/sec] (mean)보시다시피 JVM 인스턴스 (= 하나의 컴퓨터) 만 사용하기 때문에 초당 요청 요청 수가 비슷합니다.
이 시나리오에서 응용 프로그램은 확장(scale up) 만 할 수 있습니다.
노드 2개 실행
두 번째 노드를 실행하면 첫 번째 노드와 자동으로 클러스터를 형성한 다음 SortingDecider 액터를 생성하기 위해 두개의 노드가 사용됩니다. 이렇게 하면 어플리케이션은 더 많은 요청을 처리하게 됩니다. 두 번째 노드를 실행하기 위해 동일한 jar를 사용합니다. 노출된 웹 인터페이스 포트와 Akka Cluster 노드 포트를 다시 정의하면 됩니다.
java -Dapplication.exposed-port=8081 -Dclustering.port=2552 -jar target/SortingDecider-1.0-SNAPSHOT-uber.jar테스트를 실행하기 전에 간단한 라운드 로빈 기반 로드 밸런서를 설정해야 합니다. (역주: HAProxy 란)
haproxy -f src/main/resources/haproxy.conf이렇게 하면 포트 8000에서 서버가 실행되고 8080 (첫 번째 노드)과 8081 (두 번째 노드) 모두에게 트래픽이 교대로 전달됩니다. 마지막 테스트에서는 이 변경을 위해 다른 URL 파일 (shardedURLs.txt)을 사용 할 것입니다.
± % cat shardedURLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 106.80 [#/sec] (mean)
Requests per second: 108.15 [#/sec] (mean)
Requests per second: 100.60 [#/sec] (mean)
Requests per second: 99.92 [#/sec] (mean)
Requests per second: 100.07 [#/sec] (mean)보시다시피 성능이 눈에 띄게 향상 되었습니다.
우리가 배운것
우리는 이 튜토리얼에서는 다음의 내용을 배웠습니다.
- Akka 및 Spray를 사용하여 웹 응용 프로그램을 만드는 방법,
- 액터 모델을 사용하여 애플리케이션을 확장하는 방법,
- Akka 클러스터 및 Sharding 확장을 사용하여 응용 프로그램을 수평 확장하는 방법,
- 웹 애플리케이션의 성능과 확장성을 테스트하는 방법.
akka-sharding-example repository on GitHub. 저장소를 체크 아웃하여 동일한 서비스를 구현하고 동일한 성능 분석을 수행 할 수 있습니다. 이 블로그 게시물의 각 단계 (제목 참조) 에 저장소 branch 가 매칭되어 있어 있어, 보다 쉽게 사용할 수 있을 것입니다. 4단계를 구현하려면 step3 branch를 체크아웃 하고 블로그 섹션을 따르십시오.
보너스 : Akka HTTP
Spray 대신 Akka HTTP를 사용하는 저장소에 bonus branch가 있습니다. 이 구현은 약간 다르게 동작하며 가까운 미래에 이에 대해 블로그를 작성할 것입니다.