
- 전체 (687)

- 주인장 (9)
- 잡동사니 (2)
- 소프트웨어 사색 (81)
- tech shard (비공개) (0)
- 그래픽스 (3)
- 데브옵스 (5)
- 데이터 가시화 (d3.js , Plotly, Gr.. (18)
- 디자인패턴 (10)
- 무들 (moodle) (17)
- 보안 (6)
- 뱅킹 & PG (5)
- 블록체인 (55)
- 알고리즘,자료구조 (4)
- 서버 &컨테이너 & 도커등 (2)
- 오픈소스, 미들웨어 (9)
- 임베디드 (4)
- 인터프리터 (4)
- 하이브리드앱 (9)
- 아이폰 (IOS) (10)
- 안드로이드 (14)
- 운영체제 (1)
- 아마존 AWS & 클라우드 (5)
- 테스트 (1)
- 통계 & 머신러닝 & 딥러닝 (39)
- Angular & React (3)
- Akka (27)
- CUDA (1)
- Flask (5)
- Go (17)
- HAMA (3)
- Hadoop (7)
- Haskell (1)
- IoT (32)
- IoT 데이터 분석 (NILM) (10)
- IoT 전기자동차 (4)
- IDE & 기타 툴(tool) (3)
- Javascript (12)
- Java (31)
- Kotlin (10)
- Math (1)
- Netty, Java IO (8)
- Network (7)
- NoSQL (7)
- Node.js (1)
- OpenMP,PPL (4)
- OpenCV, Halcon (1)
- OpenGL , WebGL (0)
- PlayFramework2 (35)
- Amp,CUDA,OpenCL,TensorFlow (1)
- Python (37)
- RDBMS (PostgreSQL) (11)
- Scala (51)
- Spark (5)
- Spring (9)
- UI , UX 디자인 (6)
- VTK (1)
- Vert.x (13)
- WAS & 웹서버 (3)
- Zookeeper (2)
- C++ (비공개) (4)
- 문법 (1)
- TR1 (0)
- Algorithm (0)
- container (0)
- Date Time (0)
- Exception (0)
- FileSystem (0)
- Flyweight (0)
- function (0)
- Functor & binder (0)
- Geometry (0)
- Graph (0)
- IO Stream (0)
- InterProcess (0)
- Interator (0)
- Lamda (0)
- Localization & UTF-8 (0)
- log (0)
- Math, numeric (0)
- memory&pool (0)
- meta class (0)
- metwork & ASIO (0)
- PropertyTree (0)
- Regex (0)
- Signal (0)
- Singleton_template (0)
- smartptr (0)
- speed (0)
- spirit (0)
- string (0)
- system (0)
- thread & concurrent (0)
- tokenizer (0)
- util (0)
- Timer (0)
- Meeting (0)
- OpusM (0)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Hyperledger fabric gossip protocol
- 파이썬 동시성
- 스칼라 동시성
- 블록체인
- 파이썬 강좌
- CORDA
- 하이브리드앱
- Actor
- Akka
- akka 강좌
- Play2 로 웹 개발
- 파이썬
- Adapter 패턴
- 스칼라 강좌
- 그라파나
- 파이썬 데이터분석
- 엔터프라이즈 블록체인
- 이더리움
- 주키퍼
- play 강좌
- 파이썬 머신러닝
- 하이퍼레저 패브릭
- 스칼라
- 스위프트
- play2 강좌
- Play2
- 플레이프레임워크
- 안드로이드 웹뷰
- Golang
- hyperledger fabric
- Today
- Total
목록Scala (51)
HAMA 블로그
Option값이 있거나 또는 없거나 한 상태를 나타낼 수 있는 타입이다. 값이 담겨져 있는 Option 의 하위 타입은 Some[T] 이며, 값이 없으면 None 이다. Option 은 Try, Future 등과 함께 대표적인 모나딕컬렉션 이다. "컬렉션" 이다.보통 Option 을 떠올리면 2가지를 생각해야한다.1. null 을 안전하게 대체하기 위해 만들어진 것. -> 사용자에게 주의를 다시 한번 당부하는 것으로, null 예외가 발생할 확률을 없앤다.2. 연속체인에서 안정적으로 사용하기 위한 것 -> 연속으로 계산되는 상황에서 안정적으로 실행된다. 즉 중간에 문제가 생기는것을 방어한다. 주의 할 것은 방어가 되는 함수는 따로 있다는 것이며 아래 표에서 자세히 설명된다. Option 이 사용되는 경우..
List 활용 * List 는 스칼라에서 가장 많이 사용되는 데이터 구조일 겁니다.* 스칼라의 리스트는 디폴트로 불변형입니다.* 스칼라의 리스트 타입은 공변적입니다. 길이 구하기val a = List (1,2,3) a.length // 3 *배열과 달리 리스트의 length 는 비교적 비싼 연산입니다. a.isEmpty 를 a.length == 0 으로 사용하지 마세요. 양 끝에 접근하기val a = List ('a','b','c','d')a.head // 'a' 처음a.last // 'd' 마지막a.tail // List('b', 'c','d') 처음 제외 나머지 a.init // List('a','b','c') 마지막 제외 나머지 리스트 뒤집기 val a = List ('a',b','c','d')a...
 스칼라 강좌 (19) - implicit
스칼라 강좌 (19) - implicit
스칼라에서 implict 는 편하기도 하지만 코드가독성을 엄청 떨어뜨릴 수도 있기 때문에 논란이 되곤합니다. 왜 그런지 한번 살펴 볼까요? 0. 암시규칙 x + y 라는 표현식에서 타입 오류가 있다면 컴파일러는 convert(x) + y 를 시도 해봅니다. 여기서 자동으로 가져다 사용되는 convert 는 무엇일까요? convert 는 암시적으로 적용되는 변환을 목적으로 자동적으로 사용됩니다. convert 가 아래의 규칙들을 갖는다면 말이지요. 1. 표시규칙 : implicit 로 표시한 정의만 검토 대상이 된다. 즉 implicit def intToString(x : Int) = x.toString 과 같이 implict 를 붙여주면 컴파일러가 암시적 변환에 사용할 후보에 넣는다. 변수,함수,객체정의..
trait * Scala 는 interface 가 없으며 대신 trait 을 사용한다. * Scala 의 trait 는 자바의 interface 와 달리 구현 가능하다. (자바8 부터는 자바인터페이스도 디폴트메소드등 구현)* 하나의 부모클래스를 갖는 클래스의 상속과 달리 트레이트는 몇개라도 조합해 사용 가능하다. * Scala 의 trait 는 자바의 인터페이스와 추상클래스의 장점을 섞었다. * 트레이트를 믹스인 할때는 extends 키워드를 이용한다. * extends 를 사용하면 trait 의 슈퍼클래스를 암시적으로 상속하고 , 본래 trait 를 믹스인한다. * trait 는 어떤 슈퍼클래스를 명시적으로 상속한 클래스에 혼합할 수 있다. 그때 슈퍼클래스는 extends 를 사용하고, trait 는 ..
case class case 클래스 예제 abstract class Exprcase class Var(Name: String) extends Exprcase class Number(num: Double) extends Expr case class BinOp(operator: String, left:Expr , right:Expr) extends Expr * 스칼라에서 클래스 본문이 비어 있으면 중괄호를 생략할 수 있다. case 클래스 특징 * 컴파일러는 클래스 이름과 같은 이름의 팩토리 메소드를 추가한다.new Number(3.0) 대신해서 Number(3.0) 가능하다.* 케이스 클래스의 파라미터의 목록을 val 접두사를 붙인다. val n = Number(3.0) n.num // 3.0 * toSt..
Scala 에서 Enumeration 사용하기http://alvinalexander.com/scala/how-to-use-scala-enums-enumeration-examples 참조 문제 ) 스칼라에서 enumeration 을 사용하고 싶습니다.(상수로서 사용되는 문자열 ) 해결책 1 ) Enumeration 클래스를 사용해서 열거형 만들기 scala.Enumeration 클래스를 확장하세요.package com.acme.app { object Margin extends Enumeration { type Margin = Value val TOP, BOTTOM, LEFT, RIGHT = Value } } 그리고 이것을 import 로 가져가서 사용하심 됩니다object Main extends App {..
Getter 와 Setter 객체지향 프로그래밍에서 게터와 세터는 의도치 않게 이제 기본이 된 내용들 중 하나이지만 ( getter / setter 자체를 그냥 public 으로 변수 선언하는것과 마찬가지로 나쁘게 보는 시각도 있습니다. 객체지향은 외부 노출을 줄여야 한다고 보는데 게터,세터는 절차지향 마인드의 산물 ) 때로는 쓰기 귀찮아질 때 도 있긴합니다. 대부분의 게터와 세터는 매우 비슷하기 때문에 같은 기능을 하는 더 나은 방법이 있을거란 생각은 매우 타당 할 것이며 C# 에서는 그것을 위해 특별히 "프로퍼티"라는 것을 만들어서 아래와 같이 사용됩니다. private String strName; public String StrName { get { return this.strName; } set ..
함수와 메소드 이번 포스트 내용은 지금까지 그리고 앞으로 나올 강좌중에서 가장 중요한 포스트라고 생각합니다. 스칼라에서 함수/메소드는 그 만큼 중요합니다. 본 포스트의 내용이 불분명하거나 모자르면 반드시 다른 곳에서 보충하시길 바랍니다. 스칼라에서 함수종류 * 객체의 멤버로 있는 함수인 메소드 * 함수안에 정의한 내포 함수 * 함수 리터럴 * 함수 값 메소드 특성 * 스칼라 메소드 파라미터에서 중요한 점은 이들이 val 이라는것이다. def add(b : Byte) : Unit = { b = 1 // 파라미터가 val 이라 불가능 ! sum += b } * return 을 명시적으로 사용하지 말라. 스칼라는 메소드가 한 값을 계산하는 표현식인 것 처럼 생각하는걸 권장한다. * 메소드가 오직 하나의 표현식..
클래스와 객체 클래스,필드,메소드 객체 생성 클래스는 객체의 청사진이다. class ChecksumAccumulator { } 이런 클래스 가 있을때 new ChecksumAccumulator // 이렇게 해주면 객체가 만들어 진다. 클래스 안에는 필드와 메소드를 넣을 수 있다. 이 둘을 합쳐 멤버라고 한다. 필드는 var 이나 val 로 정의하며 메소드는 def 로 정의 한다. class ChecksumAccumulator { var sum = 0 } 위의 클래스를 가지고 객체를 2개 만들면 val a = new ChecksumAccumulator val b = new ChecksumAccumulator 해당 객체안의 sum 필드는 다른 메모리를 참조 할 것이고 0 을 바라 볼 것이다. sum 이 va..
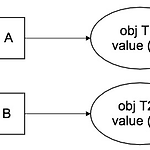 스칼라 강좌 (12) - 객체의 동일성
스칼라 강좌 (12) - 객체의 동일성
객체의 동일성 두개의 객체가 동일한지 아닌지 구분하는 작업은 별거 아닌거 같지만 , 꽤나 복잡하고 미묘한 일들이 도사리고 있습니다. 방심하다 망하죠. ;; 게다가 언어 마다 다릅니다. 테스트만이 살길~ * 2007년 상당량의 자바코드를 연구한 논문에서는 거의 대부분의 equals 메소드에 오류가 있다는 결론을 내릴 정도로 상상 이상으로 실수가 많답니다. OTL 이 글 에서는 중요 포인트만 딱딱 집어서 설명 해 보겠습니다. ( 모든 걸 설명하지 않습니다. ) 혹시 더 자세하게 파헤치고 싶은 분이라면 아래 서적을 참고 하시구요. (꼭 읽어보길 당부..) 자바 : Effective Java 2판 - 항목 8,9 스칼라 : Programming in Scala 2판 - 30장 먼저 익숙한 자바로 먼저 살펴보고,..