
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Play2 로 웹 개발
- 스위프트
- 스칼라 동시성
- Actor
- Golang
- 안드로이드 웹뷰
- CORDA
- 이더리움
- Adapter 패턴
- play2 강좌
- 엔터프라이즈 블록체인
- 파이썬 동시성
- 주키퍼
- Hyperledger fabric gossip protocol
- 파이썬 머신러닝
- play 강좌
- 그라파나
- Play2
- akka 강좌
- 하이퍼레저 패브릭
- 블록체인
- 파이썬
- 파이썬 강좌
- 스칼라 강좌
- hyperledger fabric
- 플레이프레임워크
- 파이썬 데이터분석
- 하이브리드앱
- 스칼라
- Akka
- Today
- Total
목록블록체인 (55)
HAMA 블로그
 [이더리움] Merkle Patricia Tree (MPT) 를 이해하기 위한 여정
[이더리움] Merkle Patricia Tree (MPT) 를 이해하기 위한 여정
이더리움에서 활용하고 있는 "머클 패트리샤 트리"를 이해하려다가 주화입마에 빠지신 분들이 꽤 있는거 같은데요. 사실 그것은 당신들의 탓이 아닙니다. 비탈릭이 쓴 머클링 in 이더리움 등의 블로그 글 및 각종 이더리움 책에서 설명된 내용을 읽고 금방 이해하는게 사실상 쉽지 않습니다. 남을 이해시키기 위한 글이 아니라는 생각이 들기도 하는데요. 이 글에서 저는 "이해시켜 드리기 위한 글"을 써보려고 합니다. 만약 또 실패한다면 역시 제가 모자라서 그런것이 겠지요. "개념을 이해시켜 드리기 위한 글" 이기 때문에 아주 디테일한 부분(트리에 대한 구체적 요소,추가,삭제,업데이트 및 블록상세등)을 과감히 생략하였습니다. 지엽적인 오류도 있을 수 있습니다. OTL 머클패트리샤트리를 이해하기 위해서는 먼저 몇가지 짚..
 [블록체인] 개발자를 위한 블록체인 로드맵
[블록체인] 개발자를 위한 블록체인 로드맵
- 발표시간 : 2018년 4월14일 (토요일) 3시~5시 - 발표주제 : 은행/사이버보안/선거관리/웹호스팅/도매,소매공급망/엔터네이먼트등 블록체인은 예상치 못한 방식으로 수많은 산업에 영향을 미칠 엄청난 미래 기술이 될 것이다라는 다소 과장됬을지도 모르는 글들이 쏟아져 나오는 현재 있어서, 우리 개발자들은 어떻게 보면 복받았을지도 모른다고 생각합니다. 그런 엄청난 기술에 대해서 일반인들 처럼 가쉽성 기사들만 읽고 지나가는게 아니라, 그 실체 기술이 무엇인지에 대한 호기심을 비교적 쉽게 풀 수 있기 때문인데요. 세상이 바뀌는 것에 함께 한다는 것은 꽤 멋진 일인거 같습니다. 그리고 블록체인을 공부하는 것은 우리 소프트웨어 개발자에겐 일석이조의 효과를 가져오는데요. 블록체인 자체를 알게 되는 것과 동시에,..
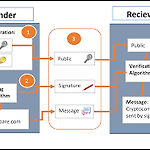 [비트코인] Raw Transaction 만들기 (sig 는 어떻게 만들어 지는가?)
[비트코인] Raw Transaction 만들기 (sig 는 어떻게 만들어 지는가?)
scriptSig 스크립트의 시작에 나오는 sig 가 어떻게 만들어지는지 궁금하진 않는가? 즉 무엇을 서명한 것인가? 그에 대한 답이 아래 코드에 있다. 이렇게 복잡하게 만들어 질 줄이야 ㅎㅎ 관련 레퍼런스: http://www.righto.com/2014/02/bitcoins-hard-way-using-raw-bitcoin.html 코드출처: https://bitcoin.stackexchange.com/questions/3374/how-to-redeem-a-basic-tx트랜잭션이 만들어지는 단계 (19단계) :4바이트의 버전 필드 추가 : 010000001바이트의 몇번째 input 인지 추가: 01우리가 소비하고자 하는 지난번 트랜잭션의 32-byte 해시: eccf7e3034189b851985d87..
 [비트코인] 머클패스의 주체는 누구? 거래검증? 거래확정?
[비트코인] 머클패스의 주체는 누구? 거래검증? 거래확정?
* 이 글은 누군가를 이해 시키기 위한 글이 아닙니다. 블록체인을 처음 만난 개발자가 비트코인의 핵심이라 할 수 있는 거래(검증)에 대한 공부/삽질을 하며 겪는 여정으로써 굉장히 불친절한 글이라는 것을 말씀드립니다. 그냥 제 삽질일기~ 그림 7-5에서는 단지 32바이트 크기의 해시 4개의 길이(총 128바이트)인 머클 경로를 생성함으로써 거래 K 가 블록 내에 포함되어 있다는 사실을 노드가 입증할 수 있다는 것을 보여준다. 머클패스는 HL .......(그림에서 파랑) 등등 이렇게 4개의 해시로 구성되어 있다. 인증 경로로 제공된 이 4개의 해시를 가지고 어떤 노드라도 4개의 해쉬에 대응하는 해시쌍인 H .... (그림에서 점선) 와 머클트리 루트를 계산함으로써 HK가 머클 루트에 포함되어 있다는 사실을..
 Economy of Things 와 블록체인
Economy of Things 와 블록체인
이름에서 느껴지듯이 Economy of Things (이하 EoT) 는 IoT 의 인프라를 이용해서 경제 활동에 이용한다는 개념인데, 블록체인과는 어떤 관계일까? 이것을 이해 하기 위해 먼저 사물인터넷과 블록체인에 대해 간단히 알아보자. IoT (사물인터넷)사물인터넷이란 각 사물들이 인터넷으로 연결 (직접 연결되지 않아도 된다. 보통 게이트웨이등을 통해서 연결됨) 되는 현상을 말하는데, 스마트폰의 확산 + 강력한 센서 + 사물로 부터 나온 빅데이터를 저장 할 수 있는 저장공간의 발전 및 기계 학습을 통한 추가정보생산이라는 저변에 의해 탄생 된 개념이다. 홈의 각 가전들도 사물이 될 수 있고, 공장의 많은 기계들도 사물이 될 수 있으며, 빌딩도 마찬가지이다. 만약 홈,공장,빌딩의 사물들에 대한 에너지를 효..