생산자 (Sender) 테스트
- 결과
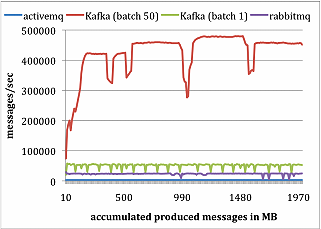
- 이유
- 카프카 생산자는 브로커로 부터의 ack 를 기다리지 않고 메세지를 보낸다.브로커가 핸들링 할수있는 만큼 빠르게 메세지를 마구 보낸다.
- 카프카는 좀더 효율적인 저장소 포맷을 가지고있다. 평균적으로 카프카 각 메세지들은 9byte 의 오버헤드를 가지며, 반면 ActiveMQ 에서는 144 bytes 를 가진다. 이것은 메세지 헤더때문인데 JMS 에 의해 요구되어진것과 다양한 인덱싱구조를 유지하기위한 것이다. LinkedIn 은 관찰하길 ActiveMQ 의 가장 바쁜쓰레드는 메세지 메타데이터와 상태를 유지하기위한 B-Tree 에 접근하기위해 대부분의 시간을 소비하는것을 발견했다.
- 결과
결과
 Reason
Reason- 카프카는 좀더 효율적인 저장소 포맷을 가지고있다. 브로커로부터 컨슈머로 데이터 이동시 아주 적은 바이트만 소비된다.
- ActiveMQ 와 RabbitMQ 의 브로커는 모든 메세지에 대한 전달 상태를 유지해야한다. LinkedIn 팀은 ActiveMQ 쓰레드들 중 하나를 관찰했는데 KahaDB 페이지를 디스크에 쓰는데 매우 바쁜걸 발견했다. 대조적으로 카프카 브로커상에서는 디스크 쓰기 행위가 없다. 결론적으로 파일에 쓰는 API 를 사용하는것에 의해 카프카는 데이터이동에 관한 오버헤드를 감소시킬수있던것이다.
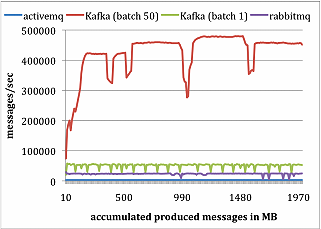
소비자 (Receiver) 테스트

RabbitMQ는 push모델이고, Kafka는 pull 모델이다. RabbitMQ는 prefetch limit라는 소비자측 옵션으로 배압(Back pressure)을 관리하고, Kafka는 소비자가 데이터를 알아서 offset을 통해 땡겨오면서 관리한다.
Kafka)
- 초당 100k+ 이상의 불같은 이벤트를 처리하려면 이용해라.
- 온라인이나 배치로 파티션된 순서로 적어도 한번은 배달될 필요가있을때
- 메세지를 다시 읽을 필요가 있을때도 사용해라. 또한 노드레벨 HA 로 흐름제한을 다룰수있을것이다.
RabbitMQ)
- 초당 20+ 메세지를 복잡한 방식으로 컨슈머에게 라우트하고 싶을때 사용하라.
- 메세지당 전달보장을 해줄필요가 있을때 사용하라.
- 배달 순서는 별로 관여치 않을때 사용하라. (순서를 보장하게도 할수있다)
- 클러스터 노드레벨의 HA 가 필요할때 사용하라.
둘다 쩌는 " Filter / Query" 능력을 제공하지는 않는다. 그러기위해서는 Storm 을 아키텍처에 추가하라
RabbitMQ vs. Kafka
- 둘다 쩌는 솔루션이다.
- RabbitMQ 가 좀더 성숙하다. (Written 12 Sep, 2012)
- 철학은 좀 다른데, 기본적으로 RabbitMQ 는 브로커 중심적이며, 생산자와 소비자간의 보장되는 메세지 전달에 촛점을 맞추었다.
- 반면 Kafka 는 생산자 중심적이며, 엄청난 이벤트 데이터을 파티셔닝하는데 기반을 둔다. 배치 소비자를 지원하며, 온라인, 오프라인에 저 지연율(Low latency)을 보장하며 메세지를 전달해준다.
- RabbitMQ 는 브로커상에서 전달 상태를 확인하기위한 메세지 표식을 사용한다. 카프카는 그런 메세지 표식이 없으며 컨슈머가 전달(배달) 상태를 기억하는것을 기대한다.
- 둘다 클러스터간의 상태를 관리하기위해 Zookeeper 를 사용한다.
- RabbitMQ 는 커다란 크기의 데이터를 위해 디자인되지 않았으며 만약 컨슈머가 매우 느리다면 실패할것이다.그러나 post 2.0 에 RabbitMQ 는 느린 배치 컨슈머를 핸들링 되는게 요청되어졌다.
- Kafka 은 오직 토픽같은 exchanges 를 사용한다. RabbitMQ 는 다양한 exchanges 를 사용한다. 토픽/큐 등
- Kafka 는 파티션들 안에서 메세지 순서를 제공하며, 파티션들간에 엄격한 순서를 가진다. 카프카 컨슈머들은 충분히 스마트해야하며 , 그들 스스로 파티션간의 순서를 해결(resolve) 해야한다.
- Kafka 는 디스크상에서 메세지를 저장하고 데이타 손실을 막기위해 클러스터로 그들을 복제한다. 각각의 성능에 큰 문제없이 브로커는 테라바이트를 핸들링할수있다. Kafka 는 쓰기에 초당 200k 메세지를 , 읽는데는 3M 메세지를 제공되도록 테스트되었다.
이 글은 2015년에 쓰여졌는데, 이전에 ESB (JBoss Fuse, Mule ESB등) 시대에는 "똑똑한 브로커에 멍청한 엔드포인트" 였다면 2020년 현재 마이크로서비스 시대인 만큼 "멍청한 브로커에 똑똑한 엔드포인트" 가치에 적합한 비동기 브리징 모델인 Kafka는 블록체인을 포함한 다양한 분야에서 대유행하고 있으며 Apache pulsar 라는 대항마도 등장했었다. MQ시장에서 Kafka가 압도적으로 사용되는 측면에는 ( 물론 RabbitMQ와 Kafka는 트레이드 오프관계로 사용 용도가 다를 수 있다. 개인적으로는 다양한 어플리케이션의 Integration 용도면 RabbitMQ/ActiveMQ/JBoss AMQ에 조금 성격은 다르지만 Camel 인데 그 이외의 용도는 모두 카프카로 대동단결하는 듯) 먼가 어렵고 귀찮은 표준(JMS, AMQP, MQTT,XMPP)같은 것과 똑똑한 브로커의 기능셋을 신경 안써도 되는 간단한 느낌?? (exactly-once 근본적문제 제외) 그리고 헤더 및 메터데이터 필요 없이 간단한 key,value기반의 pub/sub이면 충분해 받아서 쓰는건 내가 알아서 관리 할께~!! COM+/CORBA/웹서비스가 어려워서 쪼그라들고, 좀 더 쉽다는 SOA(ESB,SOAP)도 생각보다 어려워서 쪼그라든것 처럼... 누군가에겐 너무 허접한 기술인 HTML/JSON처럼 역시 세상은 쉬운 것으로 대동단결하나보다.
Kafka말고 RabbitMQ나 ActiveMQ를 꼭 써야하는 경우에 대해서 정리하면 아래와 같다.

레퍼런스)
http://mungeol-heo.blogspot.kr/2015/01/kafka-vs-rabbitmq-vs-activemq.html
http://prismoskills.appspot.com/lessons/System_Design_and_Big_Data/Chapter_12_-_RabbitMQ_vs_Kafka.jsp
http://prismoskills.appspot.com/lessons/System_Design_and_Big_Data/Chapter_12_-_RabbitMQ_vs_Kafka.jsp
https://suniphrase.wordpress.com/2015/05/07/messaging-system-comparison-kafka-vs-rabbitmq-vs-activemq/
Friday, January 2, 2015
'오픈소스, 미들웨어' 카테고리의 다른 글
| Kafka, Storm, Spark Streaming 의 메세지 보증 (0) | 2016.04.20 |
|---|---|
| RabbitMQ 사용패턴들 (0) | 2015.09.04 |
| MQTT 와 모스키토(Mosquitto) 란 무엇인가? (0) | 2015.09.03 |
| [OpenTSDB] 어떻게 OpenTSDB 는 동작하나? (0) | 2015.07.19 |
| OSGi 는 어떻게 내 삶을 변화시켰나 (번역) (0) | 2015.07.17 |