
- 전체 (687)

- 주인장 (9)
- 잡동사니 (2)
- 소프트웨어 사색 (81)
- tech shard (비공개) (0)
- 그래픽스 (3)
- 데브옵스 (5)
- 데이터 가시화 (d3.js , Plotly, Gr.. (18)
- 디자인패턴 (10)
- 무들 (moodle) (17)
- 보안 (6)
- 뱅킹 & PG (5)
- 블록체인 (55)
- 알고리즘,자료구조 (4)
- 서버 &컨테이너 & 도커등 (2)
- 오픈소스, 미들웨어 (9)
- 임베디드 (4)
- 인터프리터 (4)
- 하이브리드앱 (9)
- 아이폰 (IOS) (10)
- 안드로이드 (14)
- 운영체제 (1)
- 아마존 AWS & 클라우드 (5)
- 테스트 (1)
- 통계 & 머신러닝 & 딥러닝 (39)
- Angular & React (3)
- Akka (27)
- CUDA (1)
- Flask (5)
- Go (17)
- HAMA (3)
- Hadoop (7)
- Haskell (1)
- IoT (32)
- IoT 데이터 분석 (NILM) (10)
- IoT 전기자동차 (4)
- IDE & 기타 툴(tool) (3)
- Javascript (12)
- Java (31)
- Kotlin (10)
- Math (1)
- Netty, Java IO (8)
- Network (7)
- NoSQL (7)
- Node.js (1)
- OpenMP,PPL (4)
- OpenCV, Halcon (1)
- OpenGL , WebGL (0)
- PlayFramework2 (35)
- Amp,CUDA,OpenCL,TensorFlow (1)
- Python (37)
- RDBMS (PostgreSQL) (11)
- Scala (51)
- Spark (5)
- Spring (9)
- UI , UX 디자인 (6)
- VTK (1)
- Vert.x (13)
- WAS & 웹서버 (3)
- Zookeeper (2)
- C++ (비공개) (4)
- 문법 (1)
- TR1 (0)
- Algorithm (0)
- container (0)
- Date Time (0)
- Exception (0)
- FileSystem (0)
- Flyweight (0)
- function (0)
- Functor & binder (0)
- Geometry (0)
- Graph (0)
- IO Stream (0)
- InterProcess (0)
- Interator (0)
- Lamda (0)
- Localization & UTF-8 (0)
- log (0)
- Math, numeric (0)
- memory&pool (0)
- meta class (0)
- metwork & ASIO (0)
- PropertyTree (0)
- Regex (0)
- Signal (0)
- Singleton_template (0)
- smartptr (0)
- speed (0)
- spirit (0)
- string (0)
- system (0)
- thread & concurrent (0)
- tokenizer (0)
- util (0)
- Timer (0)
- Meeting (0)
- OpusM (0)
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 하이브리드앱
- 파이썬 동시성
- 파이썬 데이터분석
- 스칼라
- Play2 로 웹 개발
- 하이퍼레저 패브릭
- Hyperledger fabric gossip protocol
- play 강좌
- Actor
- 블록체인
- 주키퍼
- 엔터프라이즈 블록체인
- 파이썬 강좌
- 플레이프레임워크
- Adapter 패턴
- 파이썬
- 스칼라 강좌
- 이더리움
- Akka
- CORDA
- 스칼라 동시성
- Play2
- 스위프트
- play2 강좌
- 파이썬 머신러닝
- hyperledger fabric
- Golang
- 그라파나
- 안드로이드 웹뷰
- akka 강좌
Archives
- Today
- Total
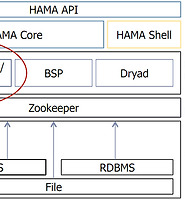
HAMA 블로그
HAMA 시작하기 본문
http://blog.udanax.org/2013/04/blog-post_29.html 펌
미리 준비해야할 것들
- Hadoop 1.0의 HDFS
- Hama 0.6 버전까지는 Hadoop 1.0과 CDH3만을 지원하고 있습니다.
- Sun/Oracle 배포 Java
- SSH
- Hama 최신버전을 다운로드 합니다.
이 글에서는 준비가 다 완료되었다고 가정하고 바로 하마 설치 들어가봅시다.
분산 모드로 설치하기
Hama 최신버전 타르볼을 압축해제한 후, 편집해야할 파일은 conf 디렉토리 밑에 groomservers, hama-env.sh, 그리고 hama-site.xml 세 개 입니다.
1) 먼저 hama-env.sh 파일을 까서, 아래와 같이 JDK가 설치된 경로와 zookeeper 실행여부를 선택합니다 (주키퍼를 설치해놓지 않았으면 true로 하고, 기존 설치된 주키퍼를 쓰려면 false로 합니다).
# The java implementation to use. Required. export JAVA_HOME=/usr/lib/jvm/java-7-oracle ... # Tell Hama whether it should manage it's own instance of Zookeeper or not. export HAMA_MANAGES_ZK=true
2) 이제 hama-site.xml 을 까서 다음과 같이 기본적으로 설정되어야할 properties를 작성해줍니다. 항목별로 설명하면 bsp 프레임워크의 마스터 서버의 호스트명과 포트번호, HDFS 파일시스템의 네임노드 호스트명과 포트번호, 주키퍼 호스트명, 그리고 인풋 데이터 파티셔닝을 실시간 처리하겠다는 설정 값들입니다.
데몬 실행 및 페이지랭크 실행해보기
설정이 끝났으면, 다음과 같이 start-bspd.sh 구동 스크립트로 데몬을 실행합니다.
<property>
<name>bsp.master.address</name>
<value>server01.udanax.org:40000</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://server01.udanax.org:9000/</value>
</property>
<property>
<name>hama.zookeeper.quorum</name>
<value>server01.udanax.org</value>
</property>
3) 여기까지 되었으면 이제 groomservers 파일을 열어서, 슬레이브로 동작할 서버들의 호스트명을 다음과 같이 나열해줍니다:server02.udanax.org server03.udanax.org server04.udanax.org ...설정이 완료되면, sever01.udanax.org 서버가 마스터로 나머지 02~04번까지의 서버가 슬레이브로 동작하게 됩니다.
데몬 실행 및 페이지랭크 실행해보기
설정이 끝났으면, 다음과 같이 start-bspd.sh 구동 스크립트로 데몬을 실행합니다.
$ bin/start-bspd.sh $ tail -f logs/hama-edward-bspmaster-udanax.org.log 2013-04-29 15:46:10,198 INFO org.apache.hadoop.ipc.Server: IPC Server Responder: starting 2013-04-29 15:46:10,198 INFO org.apache.hama.bsp.BSPMaster: Starting RUNNING 2013-04-29 15:46:21,165 INFO org.apache.hama.bsp.BSPMaster: groomd_server02.udanax.org_50000 is added.
로그를 보면 슬레이브들이 마스터서버에 추가되는 것을 볼 수 있습니다. 데몬이 잘 올라왔다면 이제 예제를 실행해볼 수 있습니다. 다음 명령어는 Pi 계산하는 예제입니다.
$ bin/hama jar hama-examples-0.6.1.jar pi 13/04/29 15:50:15 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog 13/04/29 15:50:16 INFO bsp.BSPJobClient: Running job: job_201304291546_0001 13/04/29 15:50:19 INFO bsp.BSPJobClient: Current supersteps number: 0 13/04/29 15:50:22 INFO bsp.BSPJobClient: Current supersteps number: 1 13/04/29 15:50:22 INFO bsp.BSPJobClient: The total number of supersteps: 1 13/04/29 15:50:22 INFO bsp.BSPJobClient: Counters: 6 13/04/29 15:50:22 INFO bsp.BSPJobClient: org.apache.hama.bsp.JobInProgress$JobCounter 13/04/29 15:50:22 INFO bsp.BSPJobClient: SUPERSTEPS=1 13/04/29 15:50:22 INFO bsp.BSPJobClient: LAUNCHED_TASKS=3 13/04/29 15:50:22 INFO bsp.BSPJobClient: org.apache.hama.bsp.BSPPeerImpl$PeerCounter 13/04/29 15:50:22 INFO bsp.BSPJobClient: SUPERSTEP_SUM=3 13/04/29 15:50:22 INFO bsp.BSPJobClient: TIME_IN_SYNC_MS=220 13/04/29 15:50:22 INFO bsp.BSPJobClient: TOTAL_MESSAGES_SENT=3 13/04/29 15:50:22 INFO bsp.BSPJobClient: TOTAL_MESSAGES_RECEIVED=3 Estimated value of PI is 3.1424 Job Finished in 6.432 seconds정상적으로 설치가 잘 되었다면 위와 같이 Pi 계산 결과값이 나오는것을 볼 수 있습니다. 성공하셨나요? :D 그럼 다음으로 이제 좀 더 현실적인 예제 PageRank를 계산하는 예제를 실행하려면, 먼저 generator 커맨드로 100개의 vertices와 1,000개의 edge를 갖는 랜덤 그래프 데이터를 HDFS 상에 생성합니다.
$ bin/hama jar hama-examples-0.6.1.jar gen symmetric 100 10 randomgraph 2 13/04/29 15:54:45 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog 13/04/29 15:54:46 INFO bsp.BSPJobClient: Running job: job_201304291546_0002 13/04/29 15:54:49 INFO bsp.BSPJobClient: Current supersteps number: 0 13/04/29 15:54:52 INFO bsp.BSPJobClient: Current supersteps number: 1 13/04/29 15:54:52 INFO bsp.BSPJobClient: The total number of supersteps: 1 13/04/29 15:54:52 INFO bsp.BSPJobClient: Counters: 6 13/04/29 15:54:52 INFO bsp.BSPJobClient: org.apache.hama.bsp.JobInProgress$JobCounter 13/04/29 15:54:52 INFO bsp.BSPJobClient: SUPERSTEPS=1 13/04/29 15:54:52 INFO bsp.BSPJobClient: LAUNCHED_TASKS=2 13/04/29 15:54:52 INFO bsp.BSPJobClient: org.apache.hama.bsp.BSPPeerImpl$PeerCounter 13/04/29 15:54:52 INFO bsp.BSPJobClient: SUPERSTEP_SUM=2 13/04/29 15:54:52 INFO bsp.BSPJobClient: TIME_IN_SYNC_MS=121 13/04/29 15:54:52 INFO bsp.BSPJobClient: TOTAL_MESSAGES_SENT=516 13/04/29 15:54:52 INFO bsp.BSPJobClient: TOTAL_MESSAGES_RECEIVED=516 Job Finished in 6.279 seconds그 다음 페이지랭크를 실행하면 끗~
$ bin/hama jar hama-examples-0.6.1.jar pagerank randomgraph pagerankresult 4
추가)
테스트를 위한 구성으로 3대중 1대를 NameNode, DataNode 를
나머지 2대에 DataNode를 실행해서 HDFS를 올려놓습니다.
그 다음에 3대중 1대에 BSPMaster, GroomServer, ZooKeeper 를 나머지 2대에 GroomServer를 실행합니다. 즉,
나머지 2대에 DataNode를 실행해서 HDFS를 올려놓습니다.
그 다음에 3대중 1대에 BSPMaster, GroomServer, ZooKeeper 를 나머지 2대에 GroomServer를 실행합니다. 즉,
서버1 - NameNode, DataNode, BSPMaster, GroomServer, Zookeeper
서버2 - DataNode, GroomServer
서버3 - DataNode, GroomServer
요렇게 띄워서 클러스터를 구성하면 됩니다. 설치 경로와 설정 파일은 서버 모두 동일하게 설정하셔야합니다.
'HAMA' 카테고리의 다른 글
| HAMA 쉘 분석 (0) | 2015.09.30 |
|---|---|
| [하마 인사이드] 1. HAMA with K-Means (0) | 2015.05.05 |
'HAMA' Related Articles
more

Comments