
- 전체 (687)

- 주인장 (9)
- 잡동사니 (2)
- 소프트웨어 사색 (81)
- tech shard (비공개) (0)
- 그래픽스 (3)
- 데브옵스 (5)
- 데이터 가시화 (d3.js , Plotly, Gr.. (18)
- 디자인패턴 (10)
- 무들 (moodle) (17)
- 보안 (6)
- 뱅킹 & PG (5)
- 블록체인 (55)
- 알고리즘,자료구조 (4)
- 서버 &컨테이너 & 도커등 (2)
- 오픈소스, 미들웨어 (9)
- 임베디드 (4)
- 인터프리터 (4)
- 하이브리드앱 (9)
- 아이폰 (IOS) (10)
- 안드로이드 (14)
- 운영체제 (1)
- 아마존 AWS & 클라우드 (5)
- 테스트 (1)
- 통계 & 머신러닝 & 딥러닝 (39)
- Angular & React (3)
- Akka (27)
- CUDA (1)
- Flask (5)
- Go (17)
- HAMA (3)
- Hadoop (7)
- Haskell (1)
- IoT (32)
- IoT 데이터 분석 (NILM) (10)
- IoT 전기자동차 (4)
- IDE & 기타 툴(tool) (3)
- Javascript (12)
- Java (31)
- Kotlin (10)
- Math (1)
- Netty, Java IO (8)
- Network (7)
- NoSQL (7)
- Node.js (1)
- OpenMP,PPL (4)
- OpenCV, Halcon (1)
- OpenGL , WebGL (0)
- PlayFramework2 (35)
- Amp,CUDA,OpenCL,TensorFlow (1)
- Python (37)
- RDBMS (PostgreSQL) (11)
- Scala (51)
- Spark (5)
- Spring (9)
- UI , UX 디자인 (6)
- VTK (1)
- Vert.x (13)
- WAS & 웹서버 (3)
- Zookeeper (2)
- C++ (비공개) (4)
- 문법 (1)
- TR1 (0)
- Algorithm (0)
- container (0)
- Date Time (0)
- Exception (0)
- FileSystem (0)
- Flyweight (0)
- function (0)
- Functor & binder (0)
- Geometry (0)
- Graph (0)
- IO Stream (0)
- InterProcess (0)
- Interator (0)
- Lamda (0)
- Localization & UTF-8 (0)
- log (0)
- Math, numeric (0)
- memory&pool (0)
- meta class (0)
- metwork & ASIO (0)
- PropertyTree (0)
- Regex (0)
- Signal (0)
- Singleton_template (0)
- smartptr (0)
- speed (0)
- spirit (0)
- string (0)
- system (0)
- thread & concurrent (0)
- tokenizer (0)
- util (0)
- Timer (0)
- Meeting (0)
- OpusM (0)
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬 강좌
- 스칼라
- akka 강좌
- 스칼라 동시성
- 스위프트
- Actor
- CORDA
- 주키퍼
- 플레이프레임워크
- Play2 로 웹 개발
- Adapter 패턴
- Hyperledger fabric gossip protocol
- 그라파나
- 하이퍼레저 패브릭
- play 강좌
- 파이썬 동시성
- play2 강좌
- Play2
- Akka
- 파이썬 데이터분석
- 이더리움
- 스칼라 강좌
- 하이브리드앱
- 파이썬
- 안드로이드 웹뷰
- Golang
- 파이썬 머신러닝
- 블록체인
- hyperledger fabric
- 엔터프라이즈 블록체인
- Today
- Total
목록소프트웨어 사색 (81)
HAMA 블로그
 소프트웨어는 유기물
소프트웨어는 유기물
소프트웨어 개발은 집을 짓는것 보다는 정원을 돌보는 일이라고 합니다. ㅡ실용주의 프로그래머 인용 살아 숨쉬는 녀석들을 꾸준히 관리 해 줘야 한 다는 의미겠지요. 더 이쁘고 건강 하게... 가꿀수록 좋아지는 소프트웨어 개발은 정원처럼 한번 만들고 나서 내버려두는것이 아니라, 계속 관심을 쏟는게 필요하며, 그런 의미에서 테스팅 코드, 특히 리팩토링등은 당연해 집니다.그런것을 무시 하는 관리자들이 많은데요.개발자들이 코드를 보살펴 줄 시간이 필요 하다고 하면, 말 좀 들으십시요. 다른 정원 만들라고 하지 마시고....모든 정원에 잡초와 폐자재와 쓰레기가 쌓이고 오염되는것을 원치 않는다면 말이지요.그런의미에서, 개발자들이 어떻게 보살펴 줬는지 질문하고, 확인하며, 어드바이스를 할 줄 모르는 사람이라면 개발자들을..
 굿바이~ 옵저버 패턴 and FRP
굿바이~ 옵저버 패턴 and FRP
문제 공유우리는 오랫 동안 상호작용 되는 많은 부분에 있어서 옵저버패턴을 당연하듯 활용해 왔지만,옵저버(관찰자, 소비자, 리스너) 패턴을 사용하다보면 경험 많은 개발자라면 누구나 "아 이거 먼가 깨름칙 한데" 라는 경험을 해보았을 것이다. 나 같은 평범한 개발자의 경우 그런 깨름칙한 냄새를 맡고서도, "내가 모자라서 그렇지 뭐" 자책을 하거나, "여기서 어떻게 더 잘 고칠수 있지? 옵저버패턴은 Gof 패턴 중 하나이며 훌륭한것이니 더 나은것은 없을 거야" 라고 이른 만족을 하거나, "그냥 잘 굴러가는 거 같아 보이니, 냅두자", "나는 코드를 잘 이해하고 있어, 다른 신참이나 이해 부족한 개발자 네 탓" 이 라고 기술 부채를 남기며 자기 최면을 건다든지 할 것이다. 하지만 역시 구루님들은 달랐다. 옵저버..
마이크로서비스를 넘어 서버리스 아키텍처가 유행하는 요즘(2017년) , 보다 작은 모듈단위로 강력한 힘을 가질 수 있는 golang 은 구글의 막강한 지원을 등에 업고 큰 힘을 발휘하고 있는거 같습니다. 실제 언어 순위를 매기는 각종 지표에서도 Go 는 파죽지세로 위로 솟구쳐 올라가고 있습니다. 개인적으로는 쓸데없이 복잡하다고 느끼는 소위 객체지향 언어들에 대한 염증(사실 OOP디자인을 사용하는것도 때와 시기가 있는데..무조건 적용하려고 하면.. 부작용이 생기겠지요) 과 함께 스크립트 언어들이 떴는데, (함수형도 뜨긴하지만 주력은 절대 될 수 없습니다..장담~) 그 스크립트 언어에 없는 강력함을 갖춘 언어가 Go 라서 그런거 같습니다. 즉 심플함 + 강력함 + 구글의지원 (미래보장) 아래는 요즘 흥미롭게..
 알고리즘 논란은 알고리즘으로 치유를..
알고리즘 논란은 알고리즘으로 치유를..
개인적으로 알고리즘 관련 논란에 민감한 이유실무 개발자에게 알고리즘은 덜 중요할까?알고리즘의 정체, 가치, 그리고 왜 해야 하는가? 알고리즘 논란의 마무리를 위한 에세이.. 이 전쟁을 끝내러 왔다 - 샹크스 (1) 농담이구요. 앞으로 글은 아래와 같이 3가지 다른 내용으로 간략히 쓰여질 것입니다. 지금 까지 추상적 대화만 있다고 생각해서 이 글을 쓰는 목적인 알고리즘 그 자체에 대한 이야기가 있습니다. 게운하게 기술이야기로 털고 가자는거죠. 따라서 3번만 필독 혹은 먼저 읽는것을 추천합니다. 이번 알고리즘 이야기의 끝은 알고리즘으로~ 인간,개발자vollfeed 님의 토론에 나왔던 흥미로운 기술 이야기 아하~! 알고리즘 1. 인간/개발자 레고레고를 만드는데 있어서, 이것 저것 직접 다양한 집과 비행기등을 ..
 정적타입vs동적타입?? 단순한 언어가 최고!!
정적타입vs동적타입?? 단순한 언어가 최고!!
요즘 재미있게 시청하였던 "알아두면 쓸데 없는 신비한 잡학사전: 알쓸신잡" 이라는 나PD가 만들고 유시민작가등이 출연하는 프로그램에서 따와서 "알아두면 쓸데 없는 재밌는 소프트웨어 지식: 알쓸재소" 이야기 하나 합니다. 그냥 가볍게 읽으세요~이런거 논쟁 할 시간에 실질적으로 사람들에게 필요한 서비스를 만드는데 집중 하는게 응용개발자들의 덕목이라고 생각하니까요 ~:-) https://dev.to/danlebrero/the-broken-promise-of-static-typing위의 블로그 글을 간략하게 번역/정리/추가 해본것입니다. 엉클 밥 마틴(클린코드의 저자) 은 자신의 블로그에 이런 글을 올려 놓았는데요. "타입전쟁" 로버트 마틴, Robert Martin (Uncle Bob) (@unclebobma..
 동기 I/O 와 비동기 I/O 의 성능 차이 (부록: Node.js 는 좋을게 없다.)
동기 I/O 와 비동기 I/O 의 성능 차이 (부록: Node.js 는 좋을게 없다.)
한주의 마지막이네요. 항상 건강 유념하시고~ 주말에는 푹 쉬시고 햇볕도 받으며 적절한 운동하시길 바랍니다.이번 글은 남의 글 2개를 읽고 정리 및 가벼운 코멘트 해보았습니다. 경어가 아닌점 양해해 주십시요. (_._) 비동기와 동기 네트워킹 I/O 에 대한 성능차이 위의 링크 글을 읽어보면 대략 이렇다. @ 사람이 증가할때의 초당처리율(QPS), 빨리응답해주는능력(Latency), CPU 사용율은 큰 차이 없다. @ 메모리 사용율은 큰차이로 비동기가 좋다.CPU 사용량 차이 - 거의 없다.메모리 사용량 차이 - 심하다.응답 빨리 해주는 차이 (낮을수록 좋음) - 별로 없다얼마나 많은 처리를 할 수 있나 (높을수록 좋음) - 큰 차이 없다. 따라서 메모리를 적극적으로 사용해도 문제가 없다면 그냥 동기써라~..
 [책이야기] Effective 시리즈
[책이야기] Effective 시리즈
*경어가 아닌점 양해해 주십시요. 책 광고 아닙니다 ^^ *초보자분이나 학생들에게 강추합니다. 반드시 자신의 언어에 해당되는 책을 두번,세번 읽으십시요. 나의 취미가 무엇이냐고 묻는다면, 테니스라고 서류상으로는 말은 해놓지만 실질적으로는 책 읽기/구매인거 같다. 북콜렉터!! 개인적으로 소장한 IT 계열 책만 300여권은 되는 듯하고, 10년 넘게 한달에 한번 이상 도서관에서 빌려다가 읽어보는 책도 꽤 많으니 IT 분야에서는 나름 다독가라고 할 수 있겠다.(더민주 최재천의원의 도서정가제에 원망이 많다. 어제 구입한 전문가를 위한 파이썬은 5만원이었다.RxJava를 활용한 리액티브 프로그래밍도 사야하는데 더이상의 용돈은 없다.;;) 물론 다독과 실력과는 상관관계가 많진 않다고 생각하며 , 그냥 취미 정도일 ..
제 경험이 세상의 모든 경험을 대변하지 않으며, 나는 무조건 인공지능을 하고 싶다 등의 개인의 의지 또한 별개입니다. 하고 싶으면 해야죠. 인공지능, IoT, 빅데이터, 클라우드등 취업시장에서 과장되고 있다고 느껴지는 기술들에 대한 학원 과정들에 대해서 취업자들이 선택하는데 고심을 많이 하고 있는거 같습니다. okky 게시판에도 매일 꾸준히 올라오는듯하고.그 고민/결정에 작은 도움이 되길 바랍니다. 어떤 분야가 전망이 좋다는 것과, 그 분야에서 채용이 많이 이루어진다는 별개입니다. 만약 전기자동차에 대한 전망이 좋다고 해도, 전기에너지 자체를 연구하는 사람의 수는 그리 늘지 않습니다. 생산직/세일즈맨은 거의 항상 일정 수를 유지하며 , 회사가 잘되면 그들이 더 늘어나겠지요. 또한 전기자동차를 사용하는 사..
By Eric BidelmanPublished: November 30th, 2010https://www.html5rocks.com/en/tutorials/eventsource/basics/번역 저는 웹 개발 경험이 부족하여 최근에 알게된 기술들이 많습니다. 이것도 꽤 오래된 내용인 듯 한데요. SSE (Server-Sent Events : HTML5 표준안 권고사항) 에 대해서 소개하는 글을 번역해 보았습니다. 간략하게 요약하면 이 SSE 는 어느정도 웹소켓의 역할을 하면서 더 가볍습니다. 주로 서버에서 받는 (푸쉬) 위주의 작업에 유용하게 사용 될 수 있습니다. 웹소켓과 같은 양방향은 아니기 때문에 보낼때는 Ajax 를 활용합니다. "Play2 와 Iterratee 로 채팅구현 10분완성"에서는Conc..
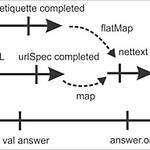 Reactive 프로그래밍 - Hello world
Reactive 프로그래밍 - Hello world
이 글은 웹 개발 파라다임의 거대한 변화 - "Reactive" 에 이어지는 코딩 위주의 글입니다. 스칼라 언어와 Play 프레임워크를 통해서 진행되니 관련 지식이 있으면 이해하기 편할 것입니다. 다만 학습을 위한 글로서는 내용이 많이 생략되어 있으며 추상층이 높아서 한번에 이해하기 원래 어려우니 자책 할 필요는 없습니다. 저도 체득하려면 멀었음을 많이 느끼고 있습니다. 완전한 이해를 하려면 여기저기 찾아다니면서 의문점을 해결해야하는 수고가 동반되며 그런면에서 Hello world 라는 제목은 좀 안어울리긴 합니다..@@ 그냥 대략 어떤것인지 맛만 본다고 생각하시고 제대로된 학습을 위해서는 나중에 기회가 되면 오프라인 모임등을 통해서 함께 하였으면 하는 마음을 전합니다. 서론자 위와 같은 프로그램을 코딩..