
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 블록체인
- akka 강좌
- 안드로이드 웹뷰
- play2 강좌
- 엔터프라이즈 블록체인
- 스위프트
- 그라파나
- 파이썬 강좌
- Golang
- Play2 로 웹 개발
- hyperledger fabric
- Adapter 패턴
- Akka
- 플레이프레임워크
- 파이썬 동시성
- CORDA
- Actor
- 하이퍼레저 패브릭
- 주키퍼
- 파이썬 머신러닝
- play 강좌
- Play2
- 스칼라
- 파이썬
- 이더리움
- 파이썬 데이터분석
- 하이브리드앱
- 스칼라 강좌
- 스칼라 동시성
- Hyperledger fabric gossip protocol
- Today
- Total
HAMA 블로그
 소프트웨어 아키텍트란
소프트웨어 아키텍트란
소프트웨어 아키텍트는 무엇인가? (개나 소나 다 자기 생각이 있는데 대충 끄젹꺼려 봄...) 보통 아키텍트 - 디자인 - 개발로 구성되는데 하이퍼레저 패브릭으로 설명 해 보면 (분야 및 조직규모등에 따라서 달라 질 순 있다) 소프트웨어 아키텍트는 "정체성" 을 확립하고 "균일성" 을 보장하는 롤을 갖는다. 즉 이 소프트웨어는 도대체 뭘 하는 것인가? 각 기업들이 서로 간의 신뢰성을 갖는데 최소의 비용으로 그것을 처리하게 하는게 목적이다. 성능 및 컨트랙트 활용성에 중점을 두고, 보안은 xxx 이상의 수준 이상으로 올리고..유저신원이 discolose 되야하고 플러그인 방식으로 컴포넌트 유연성을 갖추고..등등 이 솔루션이 커져가는데 있어서, 지켜야할 선과 확장되는데 있어서 중구난방하지 않게 사용자들이 혼동..
 [Hyperleder Fabric ] FastFabric - 20,000tps Q/A
[Hyperleder Fabric ] FastFabric - 20,000tps Q/A
FastFabric: Scaling Hyperledger Fabric to 20,000 Transactions per Second 위 논문에 대한 저자와의 질문/답변을 공개합니다. Question to U.Waterloo Improvement 1: Orderer - Seperate transaction header from payload\ - You stated that we should reduce the amount of data sent from Orderer to Kafka by keeping the RWSet at the Orderer and send only the transaction's header to Kafka - This works well when there's only one Or..
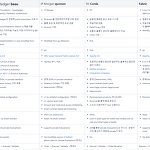 hyperledger besu vs qourum vs Corda vs Fabric
hyperledger besu vs qourum vs Corda vs Fabric
엔터프라이즈향 블록체인 비교 * fabric과 Goquorum등 모든 컨소시엄 블렉체인의 사용예에서 어떻게 거버넌스를 이루어서 어떻게 사용했다라는 구체적인 기술 정보 및 비용감소에 대한 결과 정보가 부족해서 아쉽다. (사용 결과에 대한 효율 증가 분석표같은건 기대도 안함) * 컨소시엄 블록체인을 진짜 컨소시엄을 해서 제대로 합의하고 견제하면서 하려면 Fabric을 사용해야 하는게 좋으며 (기능셋이 많다.) 좀 간략히 사용하려면 quorum이나 Besu중 아무것이나 선택해도 된다. Corda는 최근 거의 사용되지 않는 듯하며, CDBC쪽에서나 소식이 들리는 듯 하다. * 성능의 경우 체감상 예상외로 Fabric이 빠른데.. (Fabric > GoQuorum > Besu) 전체 구조상으로는 동일 RAFT컨센..
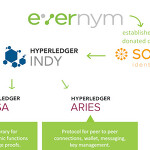 DID / SSI 를 위한 블록체인 플랫폼 - Hyperledger Indy
DID / SSI 를 위한 블록체인 플랫폼 - Hyperledger Indy
Hyperledger Indy에 대해서 정리해봤습니다. Indy는 변화,발전되고 있으며, 인사이드에 대한 정밀한 조사,검증을 하진 않았기 때문에 참고용으로만 읽어 주십시요. 4년전 처음 이글을 적을 때에는 Indy-SDK가 모든 것(블록체인과 인터페이스, DID,VC를 다루는 공통 함수들, 지갑역할, P2P역할, 익명성 역할) 을 다 담고 있었으나 2023년 3월 현재 Indy-SDK는 다양한 모듈별로 나누어진 버전들이 있습니다. (Aries, Indy-vdr,AnonCreds 등) 개요 Hyperledger Fabric과 Ethereum의 경우 Smart Contract/ChainCode 를 통해서 DID/SSI를 (저장역할을) 실현 할 수 있는 범용 플랫폼인 반면에 Indy는 오직 DID를 구축하고자..
 Go 언어에서 포인터는 언제 사용 해야 하나?
Go 언어에서 포인터는 언제 사용 해야 하나?
C++ 에서 최적화를 언급 할 때 "객체복사가 최대한 일어나지 않게 한다" 가 주요 화두를 차지 한다. ("알고리즘"을 개선하라도 중요하긴 하지만) 이에 따라서 RVO 같은 개념도 생겨나고, 아예 RVO를 믿지 못하고 매개변수에 리턴 받을 포인터를 전달하는 형태를 취하기도 한다. 마찬가지로 Go에서도 아래 처럼 *peer,Proposal 같은 포인터를 넘겨 주면서 객체복사에 대한 낭비를 줄이는데 // GetProposal returns a Proposal message from its bytes func GetProposal(propBytes []byte) (*peer.Proposal, error) { prop := &peer.Proposal{} err := proto.Unmarshal(propBytes..
 [하이퍼레저 패브릭] FastFabric - 20,000tps
[하이퍼레저 패브릭] FastFabric - 20,000tps
FastFabric: Scaling Hyperledger Fabric to 20,000 Transactions per Second 패브릭 기술에 관심있는 사람이라면 한번은 보지 않았을 까 하는 논문인데.. 과연 어떤식으로 커스터마이징을 하면 20,000 TPS를 달성 할 수 있을까? 이 논문에서는 Hyperledger Fabric 1.2 기반 (1.4에도 적용 가능)으로 아키텍쳐를 변경하여 성능을 3,000 TPS에서 20,000 TPS로 높였다고 하는데 과연 어떤 부분을 고쳐서 일까? 말이 되는 소릴 하는 걸까? 이것에 관해 각각의 토픽에 대해 배경지식/논문의 해결방식/개인적인소견(문제점)으로 정리하고자 한다. 1. Orderer - Seperate transaction header from paylo..
 [하이퍼레저 패브릭] CA,MSP,Identity Mixer 정리
[하이퍼레저 패브릭] CA,MSP,Identity Mixer 정리
이 글은 버전을 구분하지 않고 있으며 , 스스로가 공부하면서 메모식으로 두서 없이 정리/수정 하는 내용인지라 글 읽기가 힘들 수 있으며, 암호학 전문가가 아니기에 일부 오류룰 담고 있을 수 있음을 참고 하십시요. 이더리움을 위시한 퍼블릭 블록체인에서는 굳이 네트워크에 붙는 노드들에 대한 신뢰가 필요 없기 때문에, 이 글에서 설명 할 하이퍼레저 패브릭이나 코다에서 신뢰,허가 작업을 하기 위한 복잡한 CA 관련 기술이 필요 없습니다. 대신 이더리움은 아무나 참여하는 네트워크에 대한 신뢰를 다른 방식으로 추가 하기 위한 더 어려운 일에 도전하고 있는 상황입니다. 이 글에서는 하이퍼레저 패브릭과 코다에서 네트워크에 참여하는 노드들의 신뢰,허가작업들이 어떤게 있는지 살펴보겠습니다. 실제 메뉴얼들은 이 글 보다 훨..
 [하이퍼레저 패브릭] nonce
[하이퍼레저 패브릭] nonce
Hyperledger fabric 에서 reply attact 을 막기위한 nonce는 랜덤으로 생성되는데, 해당 nonce 를 가지고 TXID 도 만듭니다. 따라서 nonce 는 트랜잭션마다 가지고 있게 되며, Ledger에 그대로 저장되어 - nonce를 검증하기 위해서는 해당 트랜잭션에 대해 Ledger에 이미 동일한 TxID를 가진 트랜잭션이 있는지에 대한 중복 검사를 통해 검증됩니다. 반면 이더리움이나 쿼롬등은 nonce는 Address마다 하나씩 가지고 있으며, 하나씩 증가합니다. 따라서 Address에 있는 nonce 값과 비교해서 검증을 하게 되죠. 결국 패브릭은 엄청난 공간의 낭비, 검증의 낭비를 초래하게 되는데요.( block index 를 통해 완화하긴 합니다. 근데 용량증가시와 MV..
 [하이퍼레저 패브릭] Fabtoken의 UTXO 와 계정
[하이퍼레저 패브릭] Fabtoken의 UTXO 와 계정
@ Token Management Enablement in Hyperledger Fabric @ Using FabToken fabtoken 핵심사항 1. 패브릭에서 토큰은 어떤 자산의 형태이다. (달러같은 화폐로써 정의 될 수도 있고, 자동차, 부동산나 가격이 고정되지 않은 게임 아이템이 될 수도..) 2. 패브릭에서 토큰은 체인코드의 로직 기반으로 만들어 진다. 3. 체인코드의 오너쉽 (이더리움에서 owner 처럼) 는 체인코드가 실행 된 후에 결정 된다. 즉 패브릭 네트워크를 이루는 조직들 중에 하나가 오너쉽을 가질 수 도 있으며, 조직들이 합의한 제3의 대표조직이 가질 수도? 4. 프라이버시 및 보안 문제에 대해서도 최고의 지원을 하며 (금융에 관한 사용처에 주요함) 해당 문제가 덜 중요한 곳에서도..
 블록체인 R/D 부분 면접 오픈북
블록체인 R/D 부분 면접 오픈북
질문 리스트는 1. 블록체인 부분 2. 소프트웨어 일반/C++/Java/Go/Javascript 가 있습니다. 블록체인 부분은 블록체인 일반,이더리움,비트코인,하이퍼레저 패브릭,EOS에 한정되어 질문됩니다. 소프트웨어 부분은 저희 플랫폼이 기본적으로 성능 지향이라 C++ (17)으로 만들어져 있으며, Client SDK 는 자바로, SmartContract 와 특정서비스는 Go로 만들어지기 때문에 소프트웨어 일반과 각 언어에 대한 질문이 포함 됩니다. (모던 C++ 에 대한 깊이있는 이해는 필요. C 가 아닙니다. Go언어 전문가라면 C++에 대해서는 걱정 하지 않아도 됩니다.) 질문은 면접관이 면접자의 분야에 맞게 몇가지를 선택 (주로 형광펜 )하여서 그리고 면접자가 자신의 분야 또는 공부한 것에 대해..